Relationship between channels
[Convolution operator]
각 layer의 receptive field 내에서 spatial 및 channel-wise 정보를 융합하여 네트워크가 유익한 feature를 구성하도록 함
- SENET 중점 포인트-
1. channel과의 관계에 초점을 맞추고,
(기존 연구들은 spatial component에 중점이 맞춰 연구되었었음)
2. channel 간의 interdependencies를 명시적으로 모델링하여
channel-wise feature response을 adaptively recalibrates하는
"Squeeze-and-Excitation(SE)" block 이라는 새로운 아키텍쳐 단위 제안.
Computer Vision 연구의 중심 주제
주어진 작업에 가장 두드러진(salient) 이미지 속성만을 capture하여, 보다 강력한 representation을 찾는 것.
(input을 대표하는 속성을 찾겠다!)
최근 연구에 따르면, CNN에 의해 생성된 representation은 강화될 수 있음
(어떻게? -> 학습 메커니즘을 features 간의 spatial correlationd을 캡처하는 데 도움이 되는 네트워크와 통합함으로써)
예시)
Inception 구조 - Multi-scale process를 네트워크 module에 통합
spatial dependencies, spatial attention을 위해, 여러 연구들이 수행되었음.
이 논문에서는,
channel 간의 관계를 조사
Squeeze-and-Excitation (SE) block 제안
-> 네트워크에서 생성된 representation의 품질을 향상시키는 것을 목표로 함.
FEATURE RECALIBRATION
이를 위해 네트워크가 feature recalibration을 수행할 수 있는 메커니즘 제안
이를 통해 global information을 사용하여 유익한 feature는 강조하고 덜 중요한 feature는 억제한다.
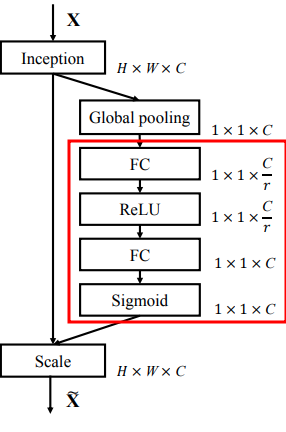
[SE BLOCK 구조]

[간략한 프로세스]
1. F_tr
주어진 변환 F_tr(e.g. convolution) 에 의해 입력 X를 feature map U에 mapping
(X -> F_tr -> U)
2. Squeeze Operation
Feature map U는 spatial dimension (H x W)에 걸쳐 feature map을 총합하여
channel descriptor을 생성하는 squeeze operation을 통해 전달.
channel descriptor의 기능은 channel-wise feature response의 global distribution의 embdding을 생성하고,
네트워크의 global receptive field로부터의 information을 모든 layer에서 사용할 수 있도록 하는 것임.
(즉, channel 별로 대표하는 값을 만들어 처리한다.)
3. excitation operation
이후 emedding을 입력으로 사용하고 per-channel modulation weight 모음을 생성하는
간단한 self-gating mechanism 형태를 취하는 작업 수행
4. Apply to feature maps
위에서 생성된 weight는 feature map U에 적용,
- SQUEEZE AND EXCITATION BLOCKS-
Convolution으로 modelling된 channel 관계는 본질적으로 지역적이고, implicit 함 (마지막 layer 제외)
SENET에서는 channel interdependencies를 explicitly 모델링하여 convolution feature의 학습이 향상되어,
informative feature에 대한 sensitivity를 증가시킬 수 있도록 기대
[Squeeze : Global Information Embeddings]
Channel dependencies exploiting 문제를 해결하기 위해,
먼저, output feature의 각 channel에 대한 signal을 고려한다.
[문제점]
학습된 filters는 local receptive field와 함께 작동하기 때문에 transformation output U의 각 unit은
local receptive field 밖의 영역의 contextual한 정보를 이용할 수 없다.
[해결책]
이 문제를 완화하기 위해 global spatial information을 channel descriptor에 squeeze할 것을 제안.(Global average pooling을 사용)
-> 위를 통한 output은 전체 이미지를 표현하는 local descriptor의 모음으로 해석될 수 있다.
[Excitation: Adaptive Recalibration]
Channel-wise dependencies를 완벽히 capture하기 위한 작업
기준
1. channel 간의 non-linear 상호작용을 학습할 수 있어야 함.
2. 여러 channel이 강조되는 것을 선호해야 함.
이를 위해 sigmoid activation function과 함께 간단한 gating mechanism 적용

위 수식은 아래 참조하면 쉽게 이해 가능
δ : ReLU


[gating mechanism]
Non-linearity 주위에 두 개의 fully connected layer(FC layer)를 배치
-> reduction ratio를 r로 설정
-> bottleneck을 형성

[Instantiations]
다른 network들과 결합 가능.
위에 reduction ratio는 hyper-parameter로 볼 수 있는데, 아래는 redunction ratio 변화에 따른 파라미터 수 및 성능 변화를 나타낸다.

'딥러닝관련 > 기초 이론' 카테고리의 다른 글
| seq2seq, attention 정리 (0) | 2021.11.08 |
|---|---|
| 선형(linear) vs 비선형(non-linear) (4) | 2021.11.05 |
| 신경망 정리 (학습 관련 기술들 - optimizer) (0) | 2021.08.16 |
| 신경망 정리 10-2 (오차 역전파 활성화 함수 계층 구현, Sigmoid) (0) | 2021.07.19 |
| 신경망 정리 10-1 (오차 역전파 활성화 함수 계층 구현, ReLU) (0) | 2021.06.13 |



