Selective Search
- 기존의 exhaustive search의 방식의 비효율성으로 "object가 있을 법한 영역만 찾는 방법"이 제안됨
- 이를 region proposal
- 이 후 detector는
1) generic detector로 candidate objects 영역을 찾기 위해 exhaustive search를 진행하고
(region proposal)
2) 이 candidate object에 대해 인식 알고리즘을 실행한다.
- 그러나 이 방법도 해결해야될 점이 있다.
→ object들이 각기 다른 shape을 가지고 있다면 windows로 scan하여 region proposal 하는 것이 옳은 방법일까?
(고정된 window 사이즈는 각기 다른 object의 size나 shape을 포착하기 어렵기 때문이다)
- 만약 object recognition을 실행하기 전에 아래와 같이 이미지를 올바르게 segment하면
segmented result에 대해서 candidate object로 사용할 수 있지 않을까?
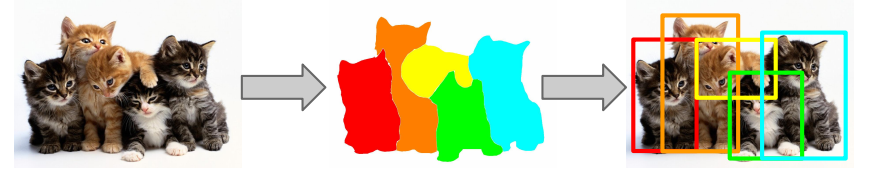
- 위 방법을 활용해서 제안한 것이 selective search
- selective search가 나올 시점에서는 기존의 방법들보다 selective search가 우수한 성능을 보임.
[Selective Search의 목표]
- object 인식이나 검출을 위한 가능한 후보 영역을 알아낼 수 있는 방법을 제공하는 것을 목표

[Selective search 과정]
1. 입력 영상에 대해 segmentation을 실시해서 이를 기반으로 후보 영역을 찾기 위한 seed를 설정
2. 초기에 엄청나게 많은 후보들이 만들어진다.
3. 이를 적절하게 통합해 나가면,
segmentation은 후보 영역의 개수가 줄어들고,
결과적으로 이를 바탕으로 box의 후보 개수도 줄어든다.
[고려사항]
1. Capture All Scales
- object는 이미지 내에서 어떤 크기(any scale)로도 나타날 수 있다.
- 또한 일부 object는 다른 object보다 boundary가 명확하지 않는다.
- 따라서 selective search에서는 모든 object의 크기(scales)를 고려해야 한다.
- 이는 hierarchical 알고리즘을 사용하여 자연스럽게 달성 가능
2. Diversification
- 영역은 색상, 질감, 또는 parts가 둘러싸여 있기 때문에 객체를 형성 가능
- 음영 및 빛의 색상과 같은 lighting condition은 regions이 물체를 형성하는 방식에 영향을 미칠 수 있음.
- 따라서, 대부분의 경우 잘 작동하는 single strategy 대신,
모든 경우를 처리할 수 있는 diverse set of strategies가 필요.
3. Fast to Compute
- selective search의 목표는 실제 object recognition framework에서 사용할 수 있는 가능한
object locations 집합을 생성하는 것
- 이 집합의 생성은 computational bottleneck이 되어서는 안된다.
- 따라서, 이 알고리즘은 빠르다.
[Selective Search Process]
1. Input 이미지에 sub-segmentation 진행
(Felzenszwalb et al Efficient Graph-Based Image Segmentation)

2. 반복적으로 작은 영역을 큰 영역으로 결합
(greedy algorithm을 사용)
1) Set of regions에서, 가장 유사한 두 가지를 선택.
2) 이 선택한 두 가지를 한 가지, 큰 영역으로 결합한다.
3) 위 1, 2 steps를 여러 iteration 동안 반복한다.

3. Segmented region proposals를 사용하여 candidate object locations를 생성

[단점]
- region proposal 과정이 실제 object detection CNN과 별도로 이루어지기 때문에,
selective search를 사용하면 end-to-end로 학습이 불가능하고, 실시간 적용에도 어려움이 있음
'딥러닝관련 > Detection' 카테고리의 다른 글
| PASCAL VOC detection 데이터 및 라벨 구조(간단히 정리) (0) | 2022.05.02 |
|---|---|
| Faster-RCNN 정리(Guide to build Faster RCNN in PyTorch) (0) | 2022.01.06 |
| Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN) 정리 (0) | 2021.11.30 |
| 병변 검출 AI 검진대회 기록 (비공개) (0) | 2021.11.29 |
| Object detection 정리 (1) (feat, object detection? , 1 stage detector, 2 stage detector) (0) | 2021.11.03 |


