아래 링크 정리 위주의 글
https://fractaldle.medium.com/guide-to-build-faster-rcnn-in-pytorch-95b10c273439
Guide to build Faster RCNN in PyTorch
Understanding and implementing Faster RCNN from scratch.
fractaldle.medium.com

[Processing time Comparison(1 image)]
Selective Search(CPU): 2 second
Fast RCNN : 2.3 second
Faster RCNN : 0.2 second ( 5 FPS )
[FLOW]
1. Region Proposal Network (RPN)
2. RPN Loss Function
3. Region of Interest Pooling (ROI)
4. ROI Loss Function
(새로운 개념의 등장)
Region Proposal Network -> Anchor Box
Training시 일반적인 흐름
1. 이미지에서 feature extraction
2. Achor targets 생성
3. Locations and objectness score prediction -> RPN network
4. 상위 N개 location 및 objectness score를 가져온다(proposal layer)
5. Fast R-CNN 네트워크를 통해 이러한 상위 N location를 전달,
각 위치에 대한 위치 및 cls 예측을 생성
6. 4에서 제안한 각 location에 대해 proposal targets을 생성
7. 2, 3을 이용하여 rpn_cls_loss와 rpn_reg_loss를 계산
8. 5, 6을 이용하여 roi_cls_loss와 roi_reg_loss를 계산
VGG16을 구성하고, 이 실험에서 back-end로 사용.
(다른 backbone model 사용 가능)
1. FEATURE EXTRACTION
아래와 같이 label 처리된 이미지와 bounding box로 시작한다.
import torch
image = torch.zeros((1, 3, 800, 800)).float() # 이미지
bbox = torch.FloatTensor([[20, 30, 400, 500], [300, 400, 500, 600]]) # [y1, x1, y2, x2] format
labels = torch.LongTensor([6, 8]) # 0 는 배경을 의미, 6, 8은 특정 클래스를 의미
sub_sample = 16
VGG16은 여기서 feature extraction module로 사용한다.
이것은 RPN과 Faster RCNN 모두에 대한 backbone 역할을 한다.
이를 위해서 VGG 네트워크에 대해서 몇 가지 변경해야 한다.
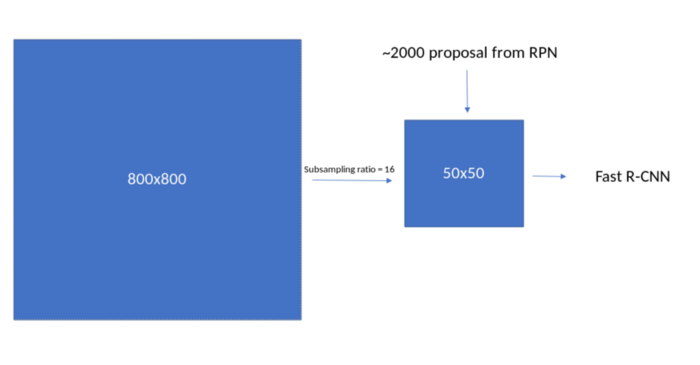
Network input이 800 x 800이기 때문에 subsampling ratio에 근거하여
feature extraction module의 output은 feature map size가 (800//16) 이어야 한다.
따라서 VGG16 모듈이 feature map 크기를 만족하는 위치를 확인하고 다듬어야 한다.
위에 대한 구체적인 단계를 살펴본다.
1. dummy 이미지를 생성하고 volatile을 false로 처리
(volatile이 torch에서 지금은 사라졌지만 true로 하면 fordward propagate 할 때만 주로 사용,
즉, inference 때 사용, false로 하면 학습을 하겠다는 의미로 보면 될 듯 하다)
import torchvision
dummy_img = torch.zeros((1, 3, 800, 800)).float()
print(dummy_img)
#Out: torch.Size([1, 3, 800, 800])
2. VGG16 layer 전체를 나열한다.
model = torchvision.models.vgg16(pretrained=True)
fe = list(model.features)
print(fe) # length is 15
# [Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False),
# Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False),
# Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False),
# Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# ReLU(inplace),
# MaxPool2d(kernel_size=(2, 2), stride=(2, 2), dilation=(1, 1), ceil_mode=False)]
3. 레이어를 통해 이미지를 전달하고 이 크기(800//16)를 얻는 위치를 확인.
req_features = []
k = dummy_img.clone()
for i in fe:
k = i(k)
if k.size()[2] < 800//16:
break
req_features.append(i)
out_channels = k.size()[1]
print(len(req_features)) #30 -> 마지막 max pooling 전까지 들어온다.
print(out_channels) # 5124. 이 리스트를 Sequential module로 바꾼다.
faster_rcnn_fe_extractor = nn.Sequential(*req_features)위에서 정의한 faster_rcnn_fe_extractor를 backend로 사용하여 feature를 계산
out_map = faster_rcnn_fe_extractor(dummy_image)
print(out_map.size())
#Out: torch.Size([1, 512, 50, 50])
2. ANCHOR BOXES
STEPS
1.
Anchor scale을 8, 16, 32
Anchor ratio를 0.5, 1, 2
subsampling ratio를 16으로 둔다.
feature map의 모든 pixel은 이미지의 해당 16 * 16 픽셀에 mapping된다.
(receptive field로 생각하면 된다)
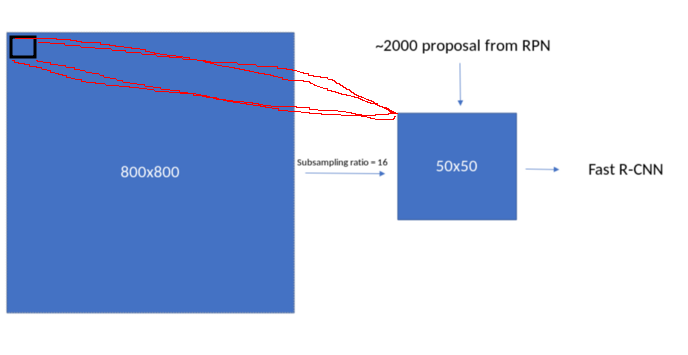
16 x 16 픽셀 위에 anchor box를 생성하고,
모든 anchor box를 가져오기 위해, x축과 y축을 따라 유사하게 생성한다.
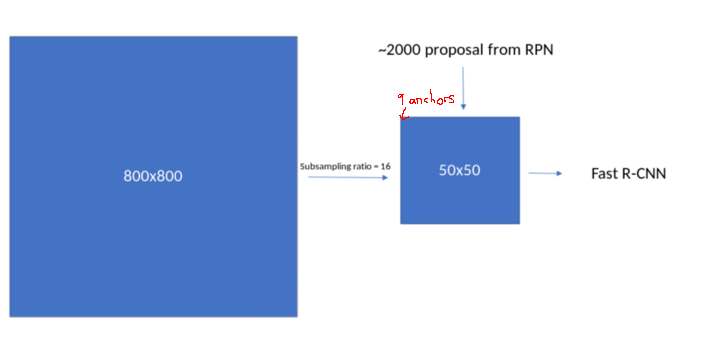
feature map의 각 pixel location에서 9개의 anchor box (anchor scale * anchor ratio)를 생성해야 하며,
각 anchor box에는 y1, x1, y2, x2가 있다.
따라서 각 feature map location에서 anchor는 (9, 4) 모양을 가진다.
(anchor scale * anchor ratio, 좌표값)
0 값으로 채워진 빈 배열이 있다고 가정
import numpy as np
ratio = [0.1, 1, 2]
anchor_scales = [8, 16, 32]
anchor_base = np.zeros((len(ratio) * len(anchor_scales), 4), dtype=np.float32)
print(anchor_base)
# [[0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]
# [0. 0. 0. 0.]]이 값들을 각각 anchor_scales 및 ratio에서 y1, x1, y2, x2로 채운다.
기본 anchor의 중심은 아래와 같다.
ctr_y = sub_sample / 2.
ctr_x = sub_sample / 2.
print(ctr_y, ctr_x)
# Out: (8, 8)
for i in range(len(ratios)):
for j in range(len(anchor_scales)):
h = sub_sample * anchor_scales[j] * np.sqrt(ratios[i])
w = sub_sample * anchor_scales[j] * np.sqrt(1./ ratios[i])
index = i * len(anchor_scales) + j
anchor_base[index, 0] = ctr_y - h / 2. # y1
anchor_base[index, 1] = ctr_x - w / 2. # x1
anchor_base[index, 2] = ctr_y + h / 2. # y2
anchor_base[index, 3] = ctr_x + w / 2. # x2
#Out:
# array([[ -37.254833, -82.50967 , 53.254833, 98.50967 ],
# [ -82.50967 , -173.01933 , 98.50967 , 189.01933 ],
# [-173.01933 , -354.03867 , 189.01933 , 370.03867 ],
# [ -56. , -56. , 72. , 72. ],
# [-120. , -120. , 136. , 136. ],
# [-248. , -248. , 264. , 264. ],
# [ -82.50967 , -37.254833, 98.50967 , 53.254833],
# [-173.01933 , -82.50967 , 189.01933 , 98.50967 ],
# [-354.03867 , -173.01933 , 370.03867 , 189.01933 ]],
# dtype=float32)이건 첫 번째 feature map pixel에 대한 anchor location
이제 Feature map의 모든 위치에서 이런 anchor box를 생성해야 함.
음수값은 anchor box가 이미지의 외부에 있다는 의미
나중에 그것들에 대해 -1로 레이블을 붙여 나중에 loss function 계산 및 proposal 생성시 제거할 것임.
각 위치에 9개의 anchor box가 있으며 feature map 사이즈는 50 x 50임.
따라서 총 17,500 (50 x 50 x 9)개의 anchor box를 얻을 것이다.
2. 모든 feature map 위치에 anchor 생성
이를 수행하려면, 먼저 모든 feature map pixel에 대한 centre(중심)을 생성해야 함.
fe_size = (800//16)
ctr_x = np.arange(16, (fe_size+1) * 16, 16)
ctr_y = np.arange(16, (fe_size+1) * 16, 16)
ctr_x 및 ctr_y를 통해 반복하면 각각의 모든 위치에 중심이 표시 가능.
아래와 같이 표시 가능 (pseudo code)
For x in shift_x:
For y in shift_y:
Generate anchors at (x, y) locations
아래는 anchor 중심에 대해 모두 표기한 이미지

Center 생성 코드
index = 0
for x in range(len(ctr_x)):
for y in range(len(ctr_y)):
ctr[index, 1] = ctr_x[x] - 8 # ctr_x, ctr_y가 16 단위로 반복했기에 여기서 8 빼줘서 중간 맞춘듯
ctr[index, 0] = ctr_y[y] - 8
index +=1
출력은 위의 이미지와 같이 각 위치의 (x, y) 값으로 보면 된다.
총 2500개의 anchor center가 있는 것이다.
각 center에서 anchor boxes 생성이 필요하다.
아래와 같이 표현 가능
anchors = np.zeros((fe_size * fe_size * 9), 4) # (50 x 50 x 9, 4)
index = 0
for c in ctr: # 위에서 정의한 center 위치
ctr_y, ctr_x = c
for i in range(len(ratios)):
for j in range(len(anchor_scales)):
h = sub_sample * anchor_scales[j] * np.sqrt(ratios[i])
w = sub_sample * anchor_scales[j] * np.sqrt(1./ ratios[i])
anchors[index, 0] = ctr_y - h / 2.
anchors[index, 1] = ctr_x - w / 2.
anchors[index, 2] = ctr_y + h / 2.
anchors[index, 3] = ctr_x + w / 2.
index += 1
print(anchors.shape)
#Out: [22500, 4]
위와 같은 방법으로 anchor box 생성 결과를 아래와 같이 시각화할 수 있다.

아래는 한 이미지에서 유효한 전체 anchor box

'딥러닝관련 > Detection' 카테고리의 다른 글
| SSD(single shot detector) 코드 분석 0. (prior box) (0) | 2022.05.17 |
|---|---|
| PASCAL VOC detection 데이터 및 라벨 구조(간단히 정리) (0) | 2022.05.02 |
| Selective Search 간단히 정리.. (0) | 2021.12.04 |
| Rich feature hierarchies for accurate object detection and semantic segmentation (R-CNN) 정리 (0) | 2021.11.30 |
| 병변 검출 AI 검진대회 기록 (비공개) (0) | 2021.11.29 |



