segmentation 작업하다가 참고해야 할 것들 간략히 정리.
나중에 디테일하게 정리해보자.
1. Ignore label
ignore index 확인 후 gradient update 안되게 지정
2. Image open

위는 open source code에 나와있는 방법
입력 이미지를 열 때 np.float32으로 열고
(입력이미지는 그냥 open하고 나중에 tensor로 바꿔도 되겠다.)
라벨 이미지를 열 때 np.int32로 연다.
조금 더 살펴보자
현재 iteration에서 위의 label을 불러왔다.
위 label에 대한 입력 이미지와 라벨 이미지는 아래와 같다.
고양이와 의자 이미지다.
위 라벨 이미지를 np.unique하여 고유값들이 어떤 것들이 있나 살펴보았다.
np.unique을 했을 때 위 label은 0, 8, 9, 255의 pixel 값들만 존재한다.
즉 0, 8, 9의 3개의 class가 존재하는 것이다.
(255 경계선에 해당하는 것들은 무시하기로 하였으므로)
Pascal VOC의 label들은 아래의 표와 같다.
"""
[
FORMAT : R G B
'background' [0, 0, 0],
'aeroplane' [128, 0, 0],
'bicycle' [0, 128, 0],
'bird' [128, 128, 0],
'boat' [0, 0, 128],
'bottle' [128, 0, 128],
'bus' [0, 128, 128],
'car' [128, 128, 128],
'cat' [64, 0, 0],
'chair' [192, 0, 0],
'cow' [64, 128, 0],
'diningtable' [192, 128, 0],
'dog' [64, 0, 128],
'horse' [192, 0, 128],
'motorbike' [64, 128, 128],
'person' [192, 128, 128],
'pottedplant' [0, 64, 0],
'sheep' [128, 64, 0],
'sofa' [0, 192, 0],
'train' [128, 192, 0],
'tvmonitor' [0, 64, 128]
]
"""
0, 8, 9에 해당하는 class는
0 : background
8 : cat
9 : chair
이므로
입력 이미지와 동일한 object들이 있는 것을 알 수 있다.
2. output, target
output shape
([batch, class, height, width])
target shape (label map)
([batch, height, width])
의 형태를 보임

nn.CrossEntropyLoss 적용할 때도 위와 같은 shape으로 연산이 들어감

보통의 task에서는 output과 target의 shape이 맞춰줘야 하지만
아래와 같이 pytorch에서 segmentation의 loss 연산을 위해
class indices의 형태를 가진 target에 대해서도 loss를 계산할 수 있게 해놓았다.
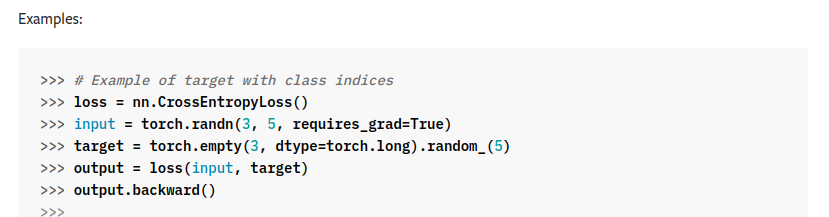
아래 코드를 통해
_, predict = torch.max(output.data, 1)max indices값들을 뽑는다.
조금 더 디테일하게 이야기를 하면
원래의 output의 shape은 위에 언급한 것과 같이
([batch, class, height, width])
으로 출력이 된다.
이를 위 코드인 torch.max를 이용해 max값에 해당하는 channel index들을 출력을 하게되면 아래와 같은 shape을 얻는다.
([batch, height, width])
이를 이미지로 보면
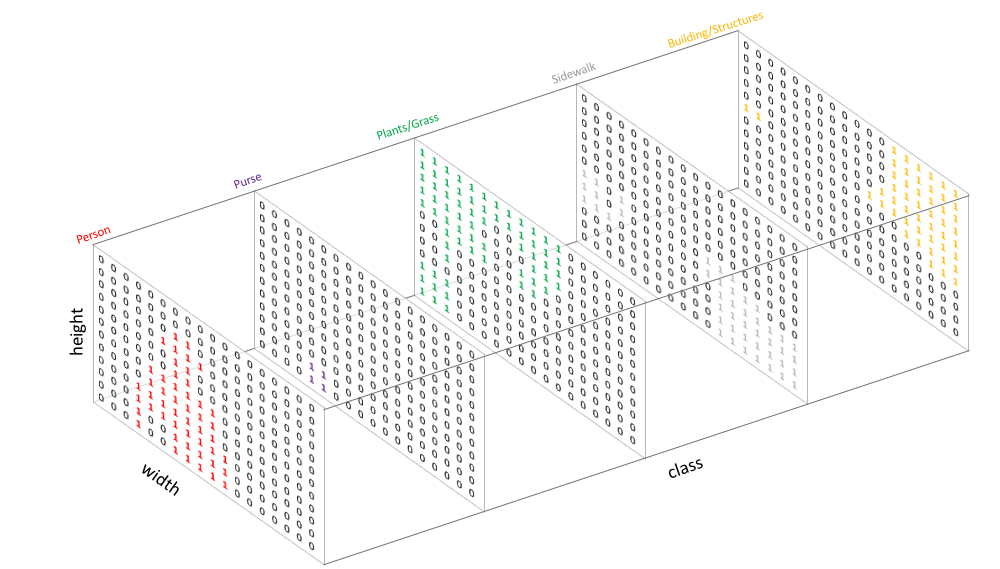
위를 모델의 출력 이미지라고 생각해보자
(실제로는 1, 0이 아닌 무수히 다른 값들이 있음)
_, predict = torch.max(output.data, 1) 를 한다면 아래와 같이 channel 간의 위치별 max값을 index 형태로 넘겨준다.
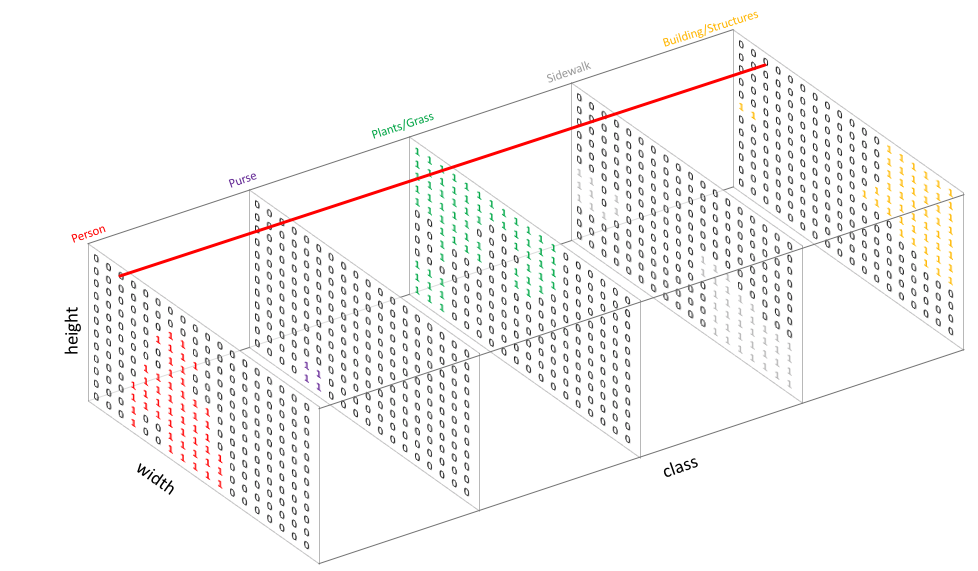
그러면 위 결과로 아래와 같은 output을 얻을 수 있는 것이다.
(위 이미지와 아래 이미지를 매칭시켜보면 머리 속에 잘 개념이 주입될듯..)
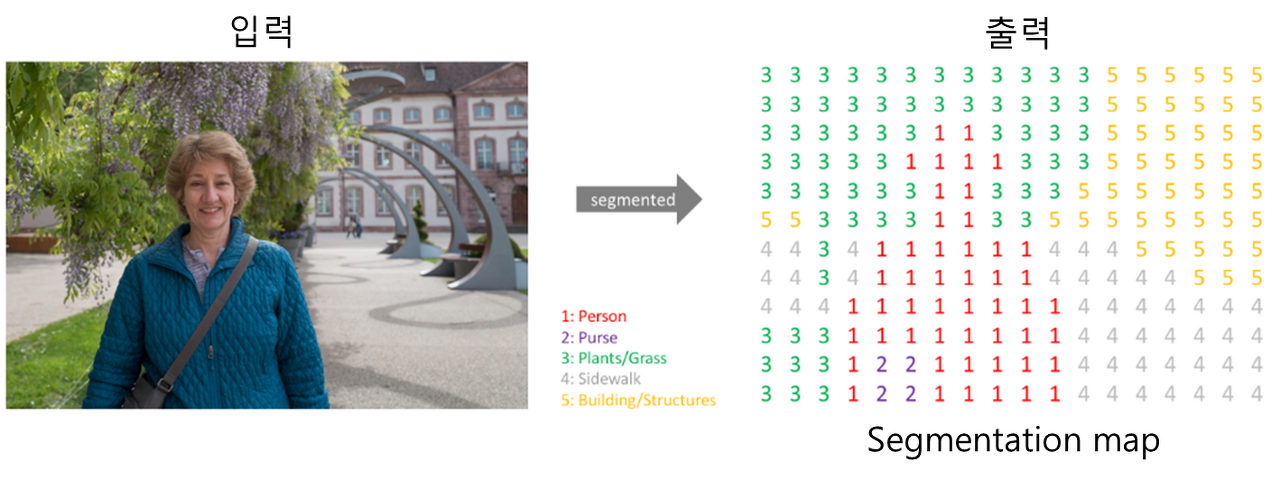
MIOU 계산시
'딥러닝관련 > Segmentation' 카테고리의 다른 글
| MMSegmentation 사용하기 (구성 확인) (0) | 2022.03.03 |
|---|---|
| MMSegmentation 사용하기 (Installation, env setting, inference with pre-trained models) (2) | 2022.03.03 |
| Image Segmentation 정리 (computer vision) (0) | 2022.01.25 |
| Fully Convolutional Networks for Semantic Segmentation (FCN) (0) | 2021.04.19 |



