
Abstract
1. Convolutional Neural Networks는 features의 hierarchies를 생성하는 강력한 visual models이며, end-to-end, pixels-to-pixel로 학습된 convolutional networks가 semantic segmentation의 state-of-the-art을 능가하는 것을 확인.
2. 임의의 크기의 입력을 받아 추론과 학습을 통해 해당 크기의 출력을 생성하는 "fully convolutional" 네트워크를 구축
Introduction
- Convolutional Networks (Convnet)는 전체 image classification을 개선할뿐만 아니라, 구조화된 출력으로 local tasks(bounding box object detection, part and keypoint prediction, 그리고 local correspondence 등) 를 진행하고 있다.
- Coarse to fine 추론으로 진행하는 다음 과정은 모든 픽셀에서 예측을 수행하는 것
- 모든 픽셀에서 예측을 수행하기 위해 end-to-end, pixels-to-pixels로 학습된 fully convolutional network(FCN)을 사용.
- 기존의 fullly convolutional 네트워크의 경우, 임의 크기의 입력에서 dense 출력을 예측한다.
- FCN의 경우 training과 inference 모두 dense feedforward computation과 backpropagation을 통해 한 번에 전체 이미지를 수행한다.
Fully Convolutional Network
1. Receptive Field
- convnet의 각 데이터 계층은 h x w x d 크기의 3 차원 배열.
- h와 w는 spatial dimension이고 d는 feature 또는 channel dimension.
- 첫 번째 레이어는 픽셀 크기가 h x w이고 색상 채널이 d 인 이미지 => (input 이미지)
- 상위 레이어의 location은 경로가 연결된 이미지의 위치에 해당 -> 이를 Receptive Field
(추가 설명)
간단히 말해 receptive field는, CNN의 feature가 보고 있는 (즉, 영향을받는) 입력 공간의 영역으로 정의가 가능하다.
receptive field 구하는 공식은 아래와 같다.

receptive field를 그림으로 보면 아래와 같다.
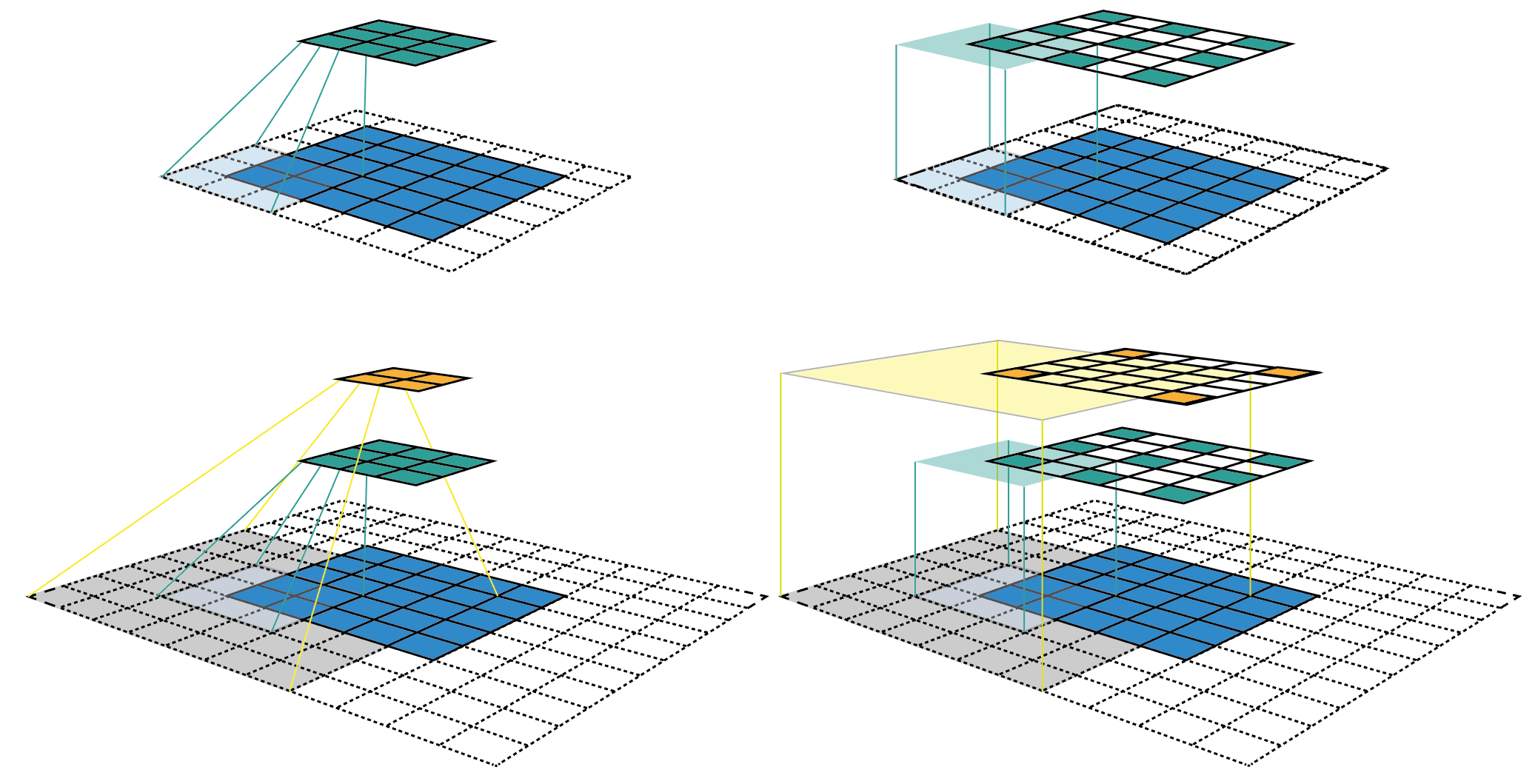
위 그림을 보면
5 x 5 input map(파란색 영역)에 padding 1, stride = 2, kernel size 3 x 3을 적용하여 3 x 3 feature map(녹색 영역)을 생성한 것을 볼 수 있고,
동일한 convolution을 적용하여 2 x 2 feature map(주황색 영역)을 생성한 것을 볼 수 있다.
오른쪽 열 이미지는 왼쪽 열 이미지를 펼쳐서 feature map의 feature가 input 이미지의 어디를 보고 있는지와 해당 영역이 얼마나 큰지 추적이 가능하다.
feature map의 모든 feature는 동일한 receptive field를 갖고 있기 때문에 하나의 feature 주위에 bouding box(점선 영역)를 그려서 receptive field의 크기를 표현할 수 있다.
2. Loss
FCN으로 구성된 real-valued loss function은 task를 정의.
loss function이 최종 레이어의 공간 차원에 대한 합계(아래)인 경우, 기울기는 각 공간 구성 요소의 기울기에 대한 합계.

따라서 전체 이미지에서 계산 된 l의 stochastic gradient descent는, final layer의 모든 receptive field를 미니 배치로 취한 l prime 의 stochastic gradient descent와 동일하다.
3. 계산 효율성
이러한 receptive field가 크게 겹치는 경우, feed forward 계산과 back propagation 모두, 패치별로 독립적으로 계산하는 대신 전체 이미지에 대해 레이어별로 계산할 때 훨씬 더 효율적.
4. Dense prediction을 위한 classifiers 개조
LeNet, AlexNet을 포함한 일반적인 인식 네트워크는 고정된 크기(fixed-sized)의 입력을 받아 non-spatial output을 생성.
(요즘 네트워크들은 꼭 고정된 크기로 받지 않는 경우도 많다)
Fully connected layers는 고정된 차원을 가지며 spatial 좌표를 없앤다.
하지만, 이 fully conneted layers를 다시 보면, 전체 input 영역을 포함하는 커널이 있는 convolution으로 볼 수도 있다.
위와 같은 관점으로 본다면 any size를 받고, classification map을 출력으로 하는 fully convolutional networks로 볼 수 있다.
그리고 위 과정을 아래의 그림으로 표현할 수 있다.
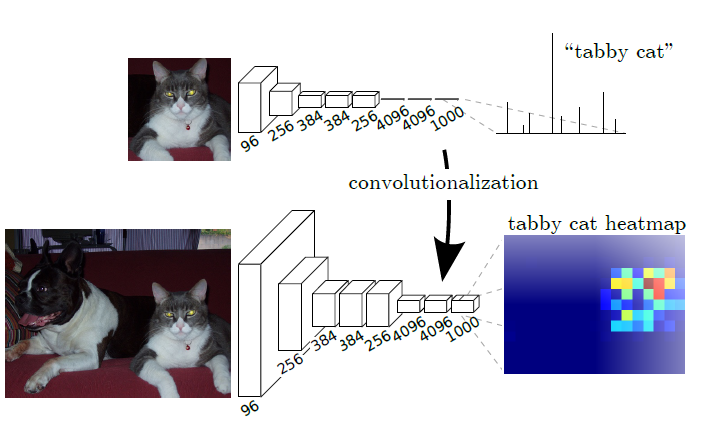
classification network를 fully convolutional으로 재해석 하면,
모든 크기(any size)의 입력에 대한 output maps가 생성되지만, output dimension은 subsampling에 의해 감소된다.
일반적인 classification network는 필터를 작게 유지하고, computational requirements를 합리적으로 유지하기 위해 sub-sampling한다.
이는, fully convolutional network의 출력을 거칠게(coarsen) 하고, output units의 receptive field의 pixel stride와 동일한 인자 만큼 입력 크기에서 감소시킨다.
(즉, 출력이 coarse하며, 입력 이미지 사이즈에 비해 훨씬 감소한다는 말을 의미)
'딥러닝관련 > Segmentation' 카테고리의 다른 글
| Segmentation 작업시 참고해야 할 것들 (간략히 정리 중) (0) | 2022.03.26 |
|---|---|
| MMSegmentation 사용하기 (구성 확인) (0) | 2022.03.03 |
| MMSegmentation 사용하기 (Installation, env setting, inference with pre-trained models) (2) | 2022.03.03 |
| Image Segmentation 정리 (computer vision) (0) | 2022.01.25 |



