< Problem >
Object detection model은 성능을 더욱 향상 시키고,
다양한 모양과 크기의 object를 capture하기 위해 아래와 같이
다양한 크기와 aspect ratios를 가진 여러 bounding box를 예측한다.

하지만, 모든 bounding box를 사용하는 건 효율적이지 않다. (high cost)
따라서, 여러 bounding box 중에서 가장 적절하며 정확한 bounding box를 선택해야 하는데 여기서 Non-maximum Suppression 의 개념이 등장한다.
< Non-maximum Suppression(NMS) >
위에서 잠시 언급했지만, 이미지 안에 object는 크기와 모양이 다를 수 있으며, 완벽하게 capture하기 위해,
object detection algorithm은 여러개의 bounding box들을 만든다.
(아래 왼쪽 이미지)
이 과정에서 수많은 proposals이 생성되고, recall이 높아져야 하므로, 이 단계에서 느슨한 contraint을 유지한다.
(즉, region proposal로 엄청나게 많은 후보 영역들이 생겨나고 이는 recall이 높아지게 한다. 그리고 처음에는 이 상태를 유지한다)

그러나 우리가 원하는 이상적인 결과는 이미지의 각 object에 대해 single bounding box다.(위 오른쪽 이미지)
이런 많은 proposals(bounding boxes)를 classification network를 통해 처리하는 건 번거롭고 비효율적이다.
여러 예측된 bounding box에서 최상의 bounding box를 선택하기 위해 NMS 알고리즘을 사용
이 기술은 가능성이 낮은 bounding box를 억제(suppress) 하고 최상의 bounding box만 유지하는 데 사용
[NMS의 목적]
object에 가장 적합한 bounding box를 선택하고, 다른 모든 bounding box에 대해서 거부하거나 억제하는 것.
NMS는 아래 두 가지를 고려한다.
1. model로부터 주어진 objectiveness score
2. bounding box의 overlap 혹은 IOU
아래 이미지에서 볼 수 있듯이, model은
bounding box와 함께 objectiveness score를 반환한다.
이 score는 model이, 원하는 object가 이 bounding box에 존재하는지에 대해서 얼마나 확신하는지를 나타냄
(모델 왈 : 그래 난 이 상자 안에 사람이 있을 확률이 96%라는 거에 내 손모가지 건다)

모든 bounding box에 object가 있는 것을 볼 수 있지만,
녹색 bounding box 하나만 object를 detecting 하는데 가장 적합한 bounding box이다.
다른 bounding box의 제거 과정은 필수로 진행해야 한다.
[과정]
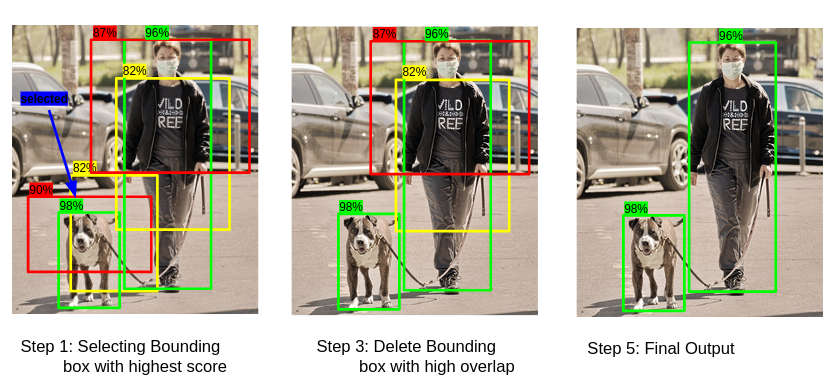
1. 먼저 objectiveness score가 가장 높은 bounding box를 선택
2. overlap이 높은 다른 모든 상자를 제거한다.
위의 이미지로 예시를 들면
1. 개에 대해 녹색 bouding box를 선택 (98%의 objectiveness score)
2. 이후 개에 대해 노란색과 빨간색 상자를 제거 (녹색과 겹치기 때문에)
위 과정으로 아래와 같은 결과가 나온다.

[NMS 알고리즘]
NMS를 사용하여 best bounding box를 선택하는 과정
1 단계 : objectiveness score가 가장 높은 box 선택
2 단계 : 그런 다음이 box의 overlap (IOU)을 다른 box들과 비교
3 단계 : IOU가 50%를 초과하는 bounding box 제거
4 단계 : 다음으로 높은 objectiveness score로 이동
5 단계 : 2-4 단계를 반복.
Input
1) Proposal box 들의 리스트 B
2) confidence scores S
3) overlap threshold N
Output
- filtered proposals D.
<알고리즘>
[step 1]
confidence score가 가장 높은 proposal을 선택
B에서 제거 후 최종 proposal list인 D에 추가
(처음에 D는 비어있음)
[step 2]
이 proposal을 다른 모든 proposals과 비교
이 proposal의 IOU를 다른 모든 proposals과 함께 계산
IOU가 threshold 값인 N보다 큰 경우 B에서 해당 proposal을 제거
[step 3]
다시, B의 나머지 proposals 중에서 가장 신뢰도가 높은 proposal을 B에서 제거 후 D에 추가
[step 4]
다시, 선택한 proposal의 IOU와 모든 proposals의 IOU 비교하여 thershold보다 높은 box를 제거
[step 5]
B에 proposal이 더 이상 남지 않을 때까지 반복
<NMS 결과>

[고려해야할 점]
NMS 알고리즘을 보면 전체 필터링 프로세스가 단일 threshold에 따라 달라진다.
따라서 threshold의 선택은 model performance의 핵심이다.
하지만 threshold를 설정하는 것은 매우 까다롭다.
만약 threshold가 0.5라면
IOU가 0.51이면서 높은 confidence score를 가진 proposal이 있으면,
다른 많은 box보다 confidence score가 높더라도 box가 제거 된다.
(Threshold를 0.5로 설정했기 때문에 confidence score 높더라도 제거)
이러한 이유로, 만약 두 object가 나란히 있으면 그 중 하나는 제거된다.
반대로, IOU가 0.49이면서 낮은 confidence score를 가진 proposal이 있으면,
다른 많은 box보다 confidence score가 낮더라도 제거되지 않는다.
아래 예시를 보자

NMS에 따라 0.9의 score를 가진 검은 박스만 유지되고 나머지 파란색, 빨간색 box들은 제거될 것이다.
-> 이는 모델의 precision을 감소시킴.
[이를 어떻게 해결??]
-> Soft-NMS를 사용
"높은 IOU와 높은 confidence score를 가진 propsal을 완전히 제거하는 대신
IOU의 값에 비례하여 proposal의 confidence를 줄임"
위 말 이미지에 대하여 아래 이미지와 같이 0.8의 confidence score를 가진 proposal에 대해서
proposal은 유지하되 confidence score는 감소 시킨다.
(0.8 -> 0.4)

위 점수 0.4는 IOU 값을 기반으로 계산된다.

아래는 Soft-NMS 논문 기반 NMS & Soft-NMS를 보여줌
Soft NMS가 NMS에 비하여 precision이 향상됨을 보임

참고
https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c
Non-maximum Suppression (NMS)
A Technique to remove duplicates and false positives in object detection
towardsdatascience.com
Selecting the Right Bounding Box Using Non-Max Suppression (with implementation)
Non-max suppression is used in various object detection algorithms like yolo, ssd. Understand how non-max suppression works with implementation.
www.analyticsvidhya.com
'딥러닝관련 > Detection' 카테고리의 다른 글
| Detectron2 (1) 환경 세팅 및 데모 (0) | 2021.09.29 |
|---|---|
| Fast R-CNN 정리 (0) | 2021.06.28 |
| Bounding box regression (0) | 2021.06.28 |
| Detection metrics 정리 (IOU, Precision, Recall, mAP...) (0) | 2021.06.18 |
| Exhaustive search (0) | 2021.06.15 |



