최대한 동작 알고리즘 순서로 맞춰 개념을 정리하고자 했다.
< Performance Metric >
< Confidence Score >
The probability that an anchor box contains an object. It is usually predicted by a classifier.
(Anchor 박스에 object가 포함될 확률 -> 이는 보통 classifier에 의해 예측됨)
박스 안에 물체가 없다면 confidence score는 0이 될거임
[box confidence score]
Pr(containing an object)⋅IoU(pred, truth)
-> 만약 object가 있으면,
[class confidence score]
Pr(classi)⋅IoU
(box confidence score×conditional class probability)
Faster RCNN의 경우 아래와 같이 RPN의 output 2k scores에서 object가 있는지 없는지를 평가한다.
(논문에서는 objectness scores라고 표현)

- Object detection은 regression과 classification task를 동시에 수행하기 때문에 어려운 task에 해당된다.
- 우선, spatial precision(공간 정밀도)을 평가하려면 low confidence를 가진 box들을 제거해야 한다.
(일반적으로 model은 실제 개체보다 더 많은 box를 출력하기 때문에 이 중 가장 object를 잘 찾는 box만 남겨야 함)
- 이 때 NMS가 사용
< Non-maximum suppresion>
2021.06.24 - [딥러닝관련/Detection] - Non-maximum Suppression
Non-maximum Suppression
일반적인 object detection process에는 classification을 위해 proposals 생성에 대한 하나의 구성 요소가 있다. Proposals는 관심 물체에 대한 candidate regions일 뿐이다. 대부분의 접근 방식은 feature map에..
better-tomorrow.tistory.com
< IoU >
- 다음, 0과 1사이인 값인 Intersection over Union(IoU) 영역을 사용한다.
- 이는 predicted box와 ground truth box의 겹친(overlapping) 영역에 해당된다.
- IoU가 높을수록 주어진 object에 대한 box의 predicted location이 더 좋다.
- 일반적으로, IoU가 일부 threshold 값보다 큰 모든 bounding box candidates를 유지.
- Precision, Recall -
- 인식/검출 기술의 성능을 평가하기 위해서는 검출율(recall)과 정확도(precision)를 동시에 고려해야 한다.
- Detection 알고리즘의 성능 평가는 mAP로 이루어진다.
- 그렇다면 Precision이 무엇인가
a. Precision
- How accurate your predictions are (즉, 검출한 결과가 얼마나 정확하냐로 볼 수 있다)
- 모델이 TRUE 라고 예측한 것들 중 실제 TRUE인 비율
- TP = True Positives - 옳은 검출
- FP = False Positives - 잘못된 검출
- Precision을 해석하면 '정밀도' 정도로 해석할 수 있다.
- 즉, 모델이 검출한 것이 얼마나 정확하냐로 precision을 정의
(모델이 10개의 검출 결과를 내보였는데 그 중 3개가 옳게 검출한 것이면 precision은 3/10)
- mean average precision이기 때문에 단순히 precision의 평균을 구하는 것으로 mAP를 측정하지 않는다.
b. Recall
- mAP를 구하기 위해서는 Recall에 대해서도 알아야 할 필요가 있다.
- Recall은 모든 positives를 얼마나 잘 찾는 지를 나타냄 (대상 물체들을 빠뜨리지 않고 얼마나 잘 잡아내는지)
- 실제 TRUE인 것들 중 모델이 TRUE로 검출한 비율
(라벨이 5개인데 그 중 true로 검출된 것이 3개면 recall은 3/5)
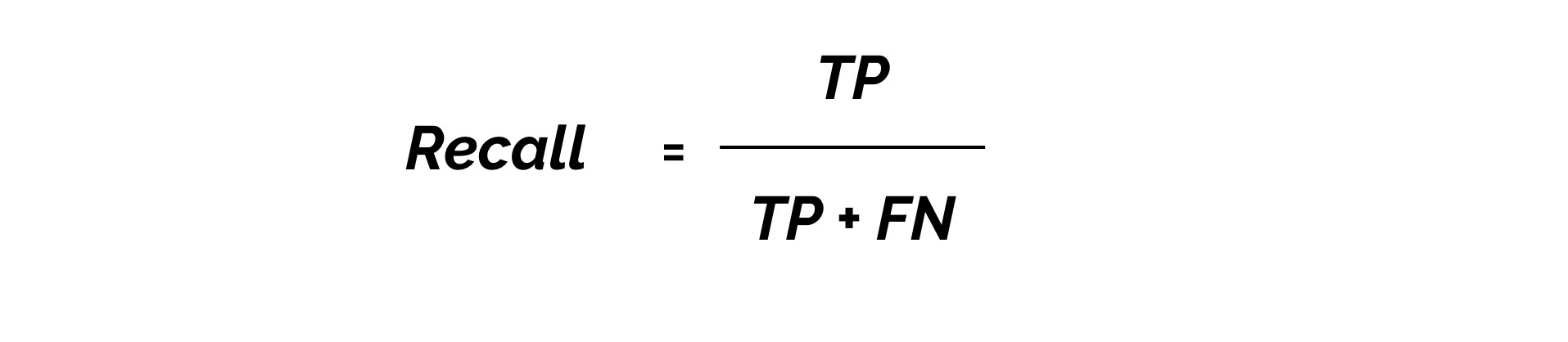
- TP = True Positives
- FP = False Negatives
여기서 잠깐, 위에 언급했던 IoU를 생각해보자.
Detection task에서는, 주어진 IoU threshold value에 대한 IoU 값을 사용하여 Precision과 Recall을 계산한다.
만약 IoU의 threshold 값이 0.5고,
prediction의 IoU value가 0.7이면, True Positive(TP)로 분류한다.
prediction의 IoU value가 0.3이라면, False Positive(FP)로 분류한다.
즉, threshold 값보다 크면 제대로 검출(True positive)되었고, threshold 값보다 작으면 잘못 검출(False Positive) 되었다고 분류하는 것.
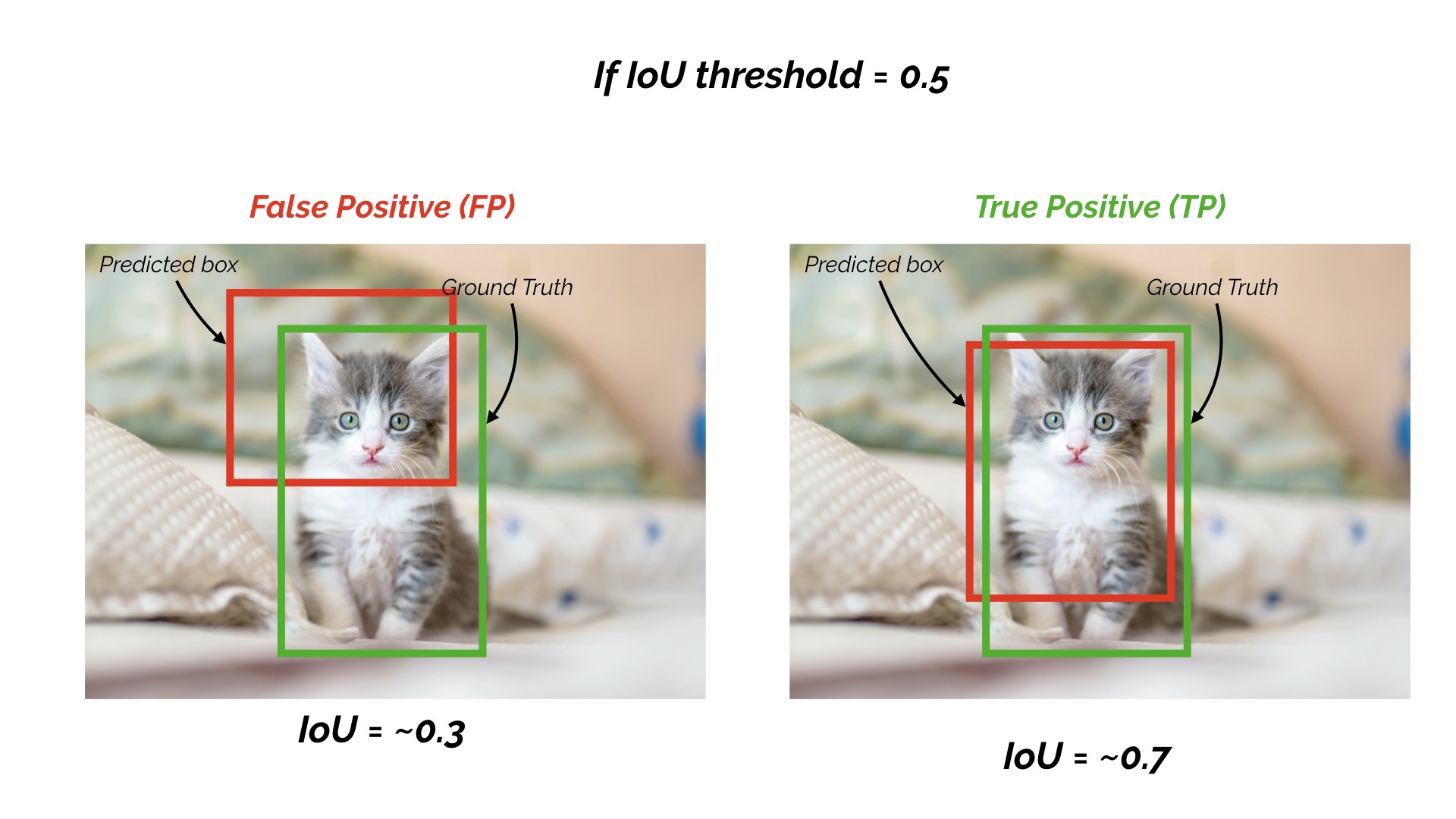
이 말인 즉, prediction의 경우 IoU threshold 값을 변경함에 따라, 아래와 같이 binary TRUE 또는 FALSE positive을 얻을 수 있음을 의미.
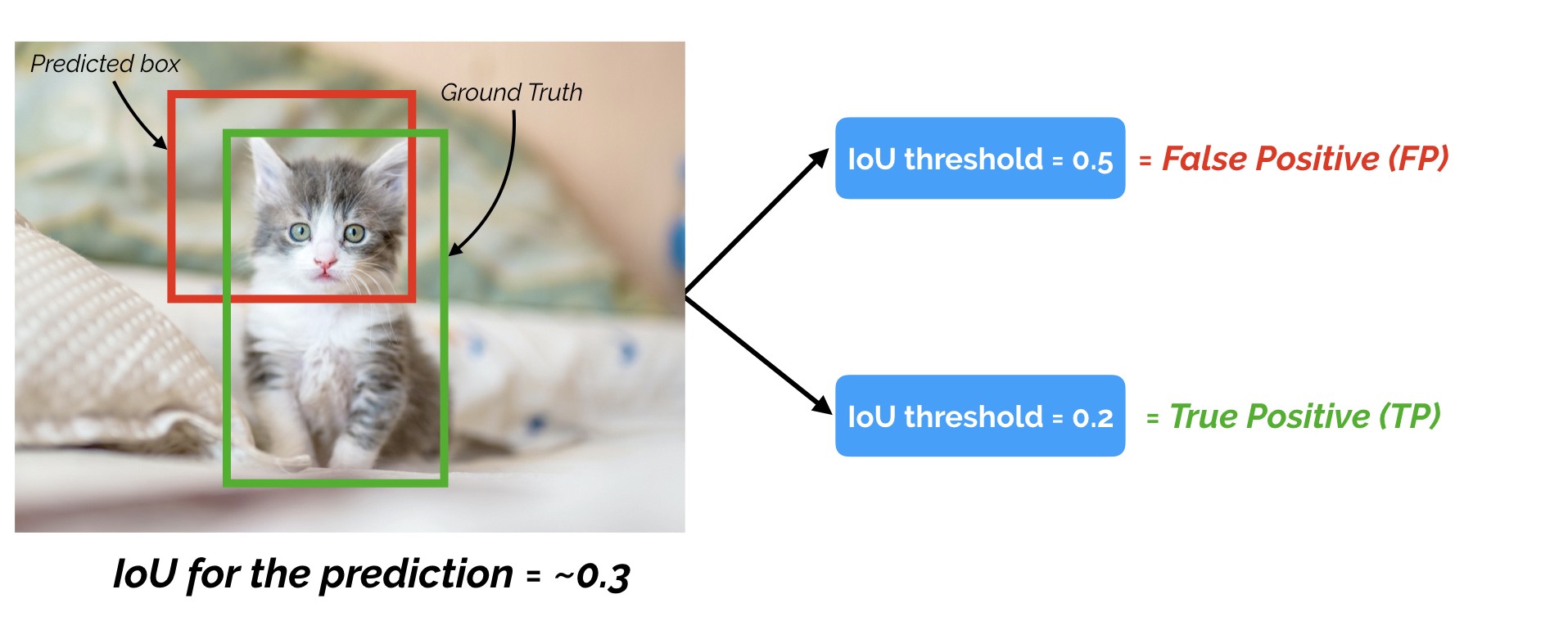
(IoU threshold가 낮으면 true positives가 증가하고, false positives가 감소하고
IoU threshold가 높으면 true positives가 감소하고, false positives가 증가한다.)
<Precision과 Recall을 모두 고려하는 이유>
Precision만으로는 물체 검출 알고리즘의 성능을 평가하는 것은 적절하지 않다.
또한 Recall만으로 성능을 평가하는 것도 적절하지 않다.
예시를 들어보자,
실제 검출되어야 하는 물체가 20개인데, 알고리즘이 검출한 물체는 10개이고, 그 중 6개가 맞다고 가정.
이때
precision : 6/10 = 0.6
recall : 6/20 = 0.3
이 나온다.
Precision으로 보면 성능이 좋아보이지만, recall로 보면 성능이 precision 보다 좋지 않다.
계산하는 방법을 보면 알다시피, precision과 recall은 0에서 1사이의 값이 나온다.
또한 precision과 recall은 반비례의 경향을 보인다.
(recall을 높이면 오검출(false positives)이 증가하고, 반대로 오검출을 줄이기 위해 조건을 강화하면 검출율이 떨어진다)
따라서 어느 한 값 만으로 알고리즘의 성능을 평가하는 것은 바람직하지 않으며,
그 두 값을 종합해서 알고리즘의 성능을 평가해야 한다.
그래서 사용하는 방법이 precision-recall 곡선이다.
이 때 옳게 검출되는 기준과 틀리게 검출한 기준을 결정하는 것이 Intersection over Union이다
- Precision-recall 곡선 -
Precision-recall 곡선은 confidence 레벨에 대한 threshold 값의 변화에 의한 물체 검출기의 성능을 평가.
알고리즘의 성능을 어느 한 값으로만 표현하고 평가하는 것은 올바른 방법이 아니다.
알고리즘의 recall과 precision은 알고리즘의 파라미터 조절에 따라 유동적으로 변하는 값이기 때문에
어느 한 값으로는 알고리즘의 전체 성능을 제대로 평가할 수 없기 때문이다.
confidence 레벨
검출한 것에 대해 알고리즘이 얼마나 확신이 있는지를 알려주는 값
값이 높을 수록 검출한 결과에 큰 확신이 있다는 것
그러나, 말 그대로 알고리즘이 확신하다고 하는 것이지, confidence 레벨이 높다고 검출 성능이 정확한 것은 아니다.
따라서 보통은 confidence level에 대해 threshold 값을 부여해서 그 이상이 되어야 검출한 것으로 인정한다.
이 confidence 레벨에 대한 threshold 값의 변화에 따라, precision과 recall 값들도 달라진다.
이것을 그래프로 나타낸 것이 precision-recall 그래프.
예시
15개의 얼굴이 존재하는 얼굴 데이터 (ground truth)
총 10개의 얼굴이 검출됨 (model output)
이때의 검출 결과
(confidence score + TP or FP 포함)
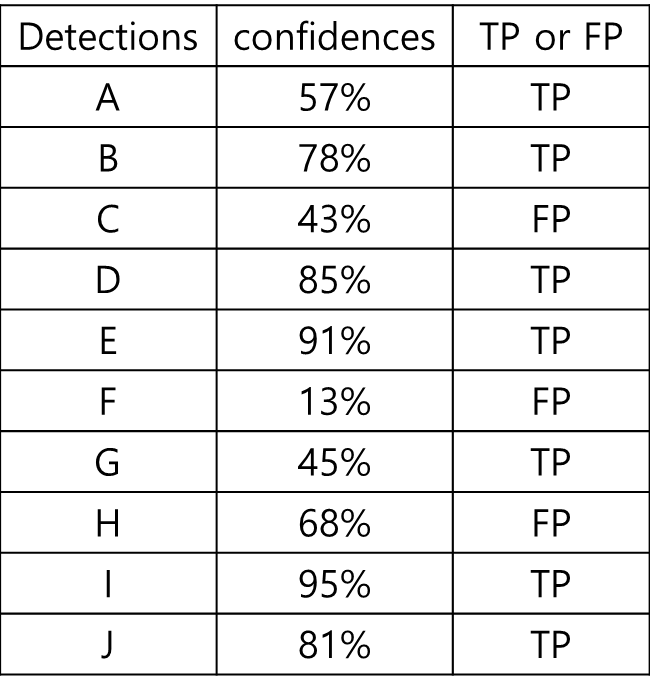
위를 보면 10개 중 7개가 제대로 검출되었고(TP), 3개가 오검출 되었다(FP).
# of Groud truth : 15
# of output : 10
# of TP : 7
# of FP : 3
Precision : 7/10 = 0.7
(TP / output)
Recall : 7 / 15 = 0.47
(TP / ground truth)
위 결과는 confidence 레벨이 13%와 같이 낮은 것도 모두 검출했을 때의 결과
confidence score를 재 정렬
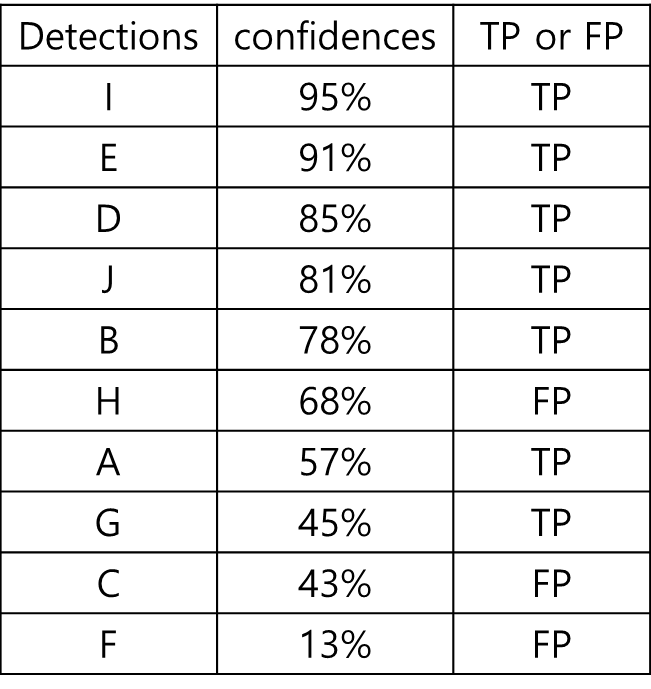
위 재정렬한 결과들 중 confidence 레벨에 대한 threshold를 95%로 적용했으면,
한개만 검출한 것으로 판단.
이 때,
Precision : 1 / 1 = 1
Recall : 1 / 15 = 0.067
이 된다.
threshold를 91% 낮추면
Precision : 2 / 2 = 1
Recall : 2 / 15 = 0.067
가 된다.
Threshold 값을 결과의 confidence 레벨에 맞춰 나가면 아래와 같은 계산 결과가 나올 수 있음
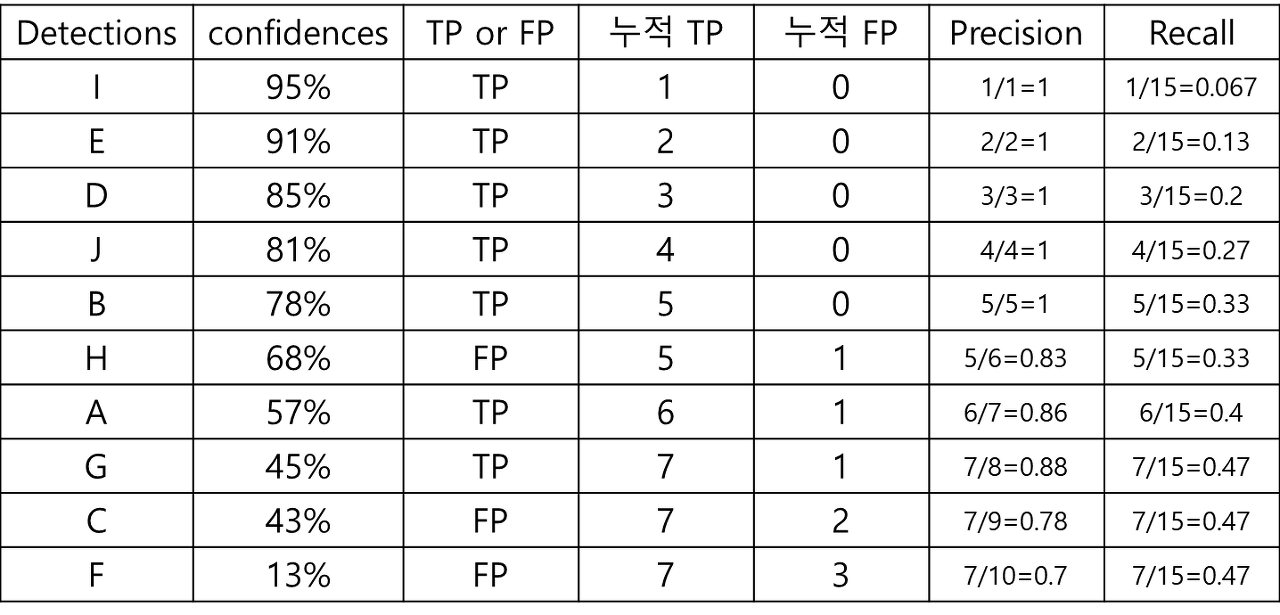
이 Precision값들과 recall 값들을 그래프로 나타내면 precision-recall 곡선

그래프의 x축은 recall, y축은 precision
recall 값의 변화에 따른 precision 값을 확인 가능
4) Average Precision
Precision-recall 그래프는 어떤 알고리즘의 성능을 전반적으로 파악하기에는 좋으나
서로 다른 두 알고리즘의 성능을 정량적으로 비교하기에는 불편한 점이 있다.
Precision-recall 그래프를 하나의 숫자로 성능을 평가하기 위해 나온 것이 Average Precision
Average Precision(AP)의 일반적인 정의는 precision-recall curve 아래 영역으로 계산된다.
Average precision이 높으면 그 알고리즘의 성능이 우수하다고 평가한다.
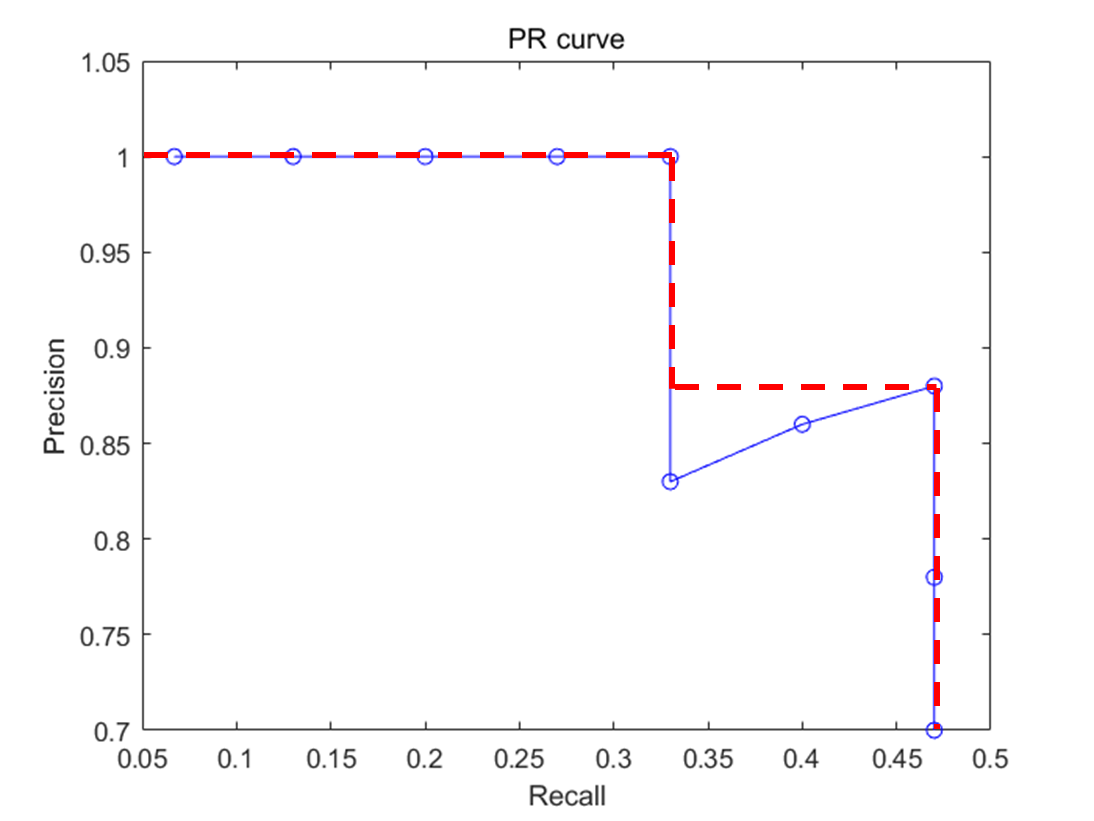
보통 계산 전 위와 같이 곡선을 살짝 조정한다. -> 단조적으로 감소하는 그래프로
조정 후 그래프 선 아래의 넓이를 계산함으로써 average precision을 구한다.
위는 큰 사각형과, 작은 사각형의 넓이를 계산해서 구할 수 있다.
컴퓨터 비전 분야에서 물체 검출 및 이미지 분류 알고리즘의 성능은 대부분 average precision으로 평가
물체의 클래스가 여러 개인 경우
각 클래스당 AP를 구한 다음 그것의 평균으로 성능을 측정한다.
이를 mAP(mean Average Precision)이라고 한다.
<1 or 2 stage detector>
Object Detection은 크게 1 stage detector와, 2 stage detector로 나눌 수 있다.
1 stage detector : region proposal과 classification이 동시에 이루어짐
2 stage detector : region proposal과 classification이 순차적으로 이루어짐
참고
http://vision.stanford.edu/teaching/cs231b_spring1415/slides/ssearch_schuyler.pdf
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
Review of Deep Learning Algorithms for Object Detection
Why object detection instead of image classification?
medium.com
https://towardsdatascience.com/map-mean-average-precision-might-confuse-you-5956f1bfa9e2
mAP (mean Average Precision) might confuse you!
Spoiler Alert: mAP is NOT the average of precision.
towardsdatascience.com
물체 검출 알고리즘 성능 평가방법 AP(Average Precision)의 이해
물체 검출(object detection) 알고리즘의 성능은 precision-recall 곡선과 average precision(AP)로 평가하는 것이 대세다. 이에 대해서 이해하려고 한참을 구글링했지만 초보자가 이해하기에 적당한 문서는 찾
bskyvision.com
https://darkpgmr.tistory.com/162?category=460965
precision, recall의 이해
자신이 어떤 기술을 개발하였다. 예를 들어 이미지에서 사람을 자동으로 찾아주는 영상 인식 기술이라고 하자. 이 때, 사람들에게 "이 기술의 검출율은 99.99%입니다"라고 말하면 사람들은 "오우..
darkpgmr.tistory.com
An Introduction to Evaluation Metrics for Object Detection | NickZeng|曾广宇
Introduction The purpose of this post was to summarize some common metrics for object detection adopted by various popular competetions. This post mainly focuses on the definitions of the metrics; I’ll write another post to discuss the interpretaions and
blog.zenggyu.com
'딥러닝관련 > Detection' 카테고리의 다른 글
| Detectron2 (1) 환경 세팅 및 데모 (0) | 2021.09.29 |
|---|---|
| Fast R-CNN 정리 (0) | 2021.06.28 |
| Bounding box regression (0) | 2021.06.28 |
| Non-maximum Suppression (0) | 2021.06.24 |
| Exhaustive search (0) | 2021.06.15 |



