https://better-tomorrow.tistory.com/entry/Word-Embedding 이후 내용
- 단어의 '의미'를 다차원 공간에 벡터화하는 방법을 distributed represenation ▶ dense vector
1. Distributed represenation
- Distributional hypothesis라는 가정하에 만들어진 표현 방법
- 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다
- 강아지 ▶ 귀엽다 / 예쁘다 (강아지라는 단어가 뜨면 "귀엽다", "예쁘다" 라는 단어가 함께 등장)
- 분포 가설에 근거 ▶ 저런 내용을 가진 텍스트를 벡터화하면 의미적으로 가까운 단어
- Distributional hypothesis을 이용하여 단어들의 셋을 학습 ▶여러 차원에 분산하여 표현
Ex) 고양이 = [0.23 0.11 0.43 0.75 0.43 ...... 0.11]
▶ Sparse representation : 고차원에 각 차원이 분리된 표현 방법
▶ Distributed representation : 저차원에 단어의 의미를 여러 차원에다가 분산하여 표현 → 단어간 유사도 계산 가능
2. Continus Bag of Words (CBOW) (Word2Vec 1)
- 주변에 있는 단어들로 중간 단어들 예측
ex) 예시 " The cat sat on the mat"
≫ "set"을 예측한다고 가정. {"The", "fat", "cat", "on", "the", "mat"}으로부터 sat을 예측
- sat을 중심 단어 (center word)
- 나머지 단어들을 주변 단어 (context word)
- 중심 단어 예측을 위해 앞, 뒤로 몇개의 단어를 볼지 범위, 윈도우 (window), 선택
- sat을 예측한다면 fat, cat & on, the 참고
- 윈도우 크기가 n이라고하면, 참고하는 주변 단어 개수는 2n개
- 윈도우 크기 정한 후, 윈도우를 움직어 주변 단어와 중심 단어 선택을 바꿔가며 학습을 위한 데이터 셋 생성
(siliding window 기법)

- Word2Vec에서 입력은 모두 one-hot vector가 되어야 한다.

- 위는 CBOW 신경망 학습 과정(deep learning model)은 아님 - 하나의 hidden layer만 존재 → projection layer
- activation function이 존재하지 않음
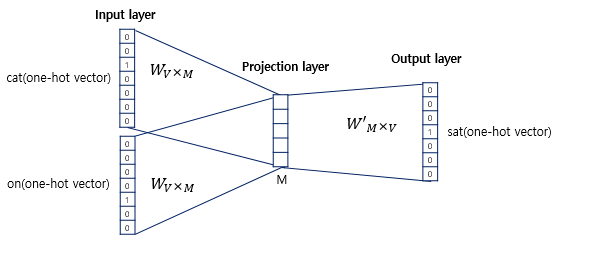
- 위는 CBOW 신경망 학습 과정(deep learning model)은 아님 - 하나의 hidden layer만 존재
- activation function이 존재하지 않음
- CBOW를 수행하고나서 얻은 projection layer의 벡터의 차원은 5
- input layer와 projection layer의 weight는 V x M 행렬
- projection layer와 output layer의 weight는 M X V 행렬
ex) one-hot vector의 차원이 7이고 M은 5라면 input-projection layer사이의 weight는 7 x 5 행렬이고,
projection layer-output layer의 weight는 5 x 7

- 위는 학습 과정
- 주변 단어의 one-hot vector를 x로 표기
3. Skip-Gram (Word2Vec 2)
- 중간에 있는 단어로 주변 단어 예측
'딥러닝관련 > 자연어처리' 카테고리의 다른 글
| 자연어 처리란 (0) | 2021.12.15 |
|---|---|
| Transformer Decoder : Linear & Softmax Layer (0) | 2021.11.16 |
| Transformer Decoder : Encoder-Decoder Attention (0) | 2021.11.16 |
| StackGAN 논문 리뷰(작성 중) (0) | 2020.07.16 |
| Word Embedding (0) | 2020.07.13 |


