[Transformer]
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
Transformer가 나온 이후 자연어 처리에서 이미 많이 쓰이고
computer vision 분야에서는 최근에서야 transformer 기반 모델들이 SOTA를 기록하고 있다.
그 시작 논문은 아래와 같다.
https://arxiv.org/pdf/2010.11929.pdf
[Transformer in Vision]
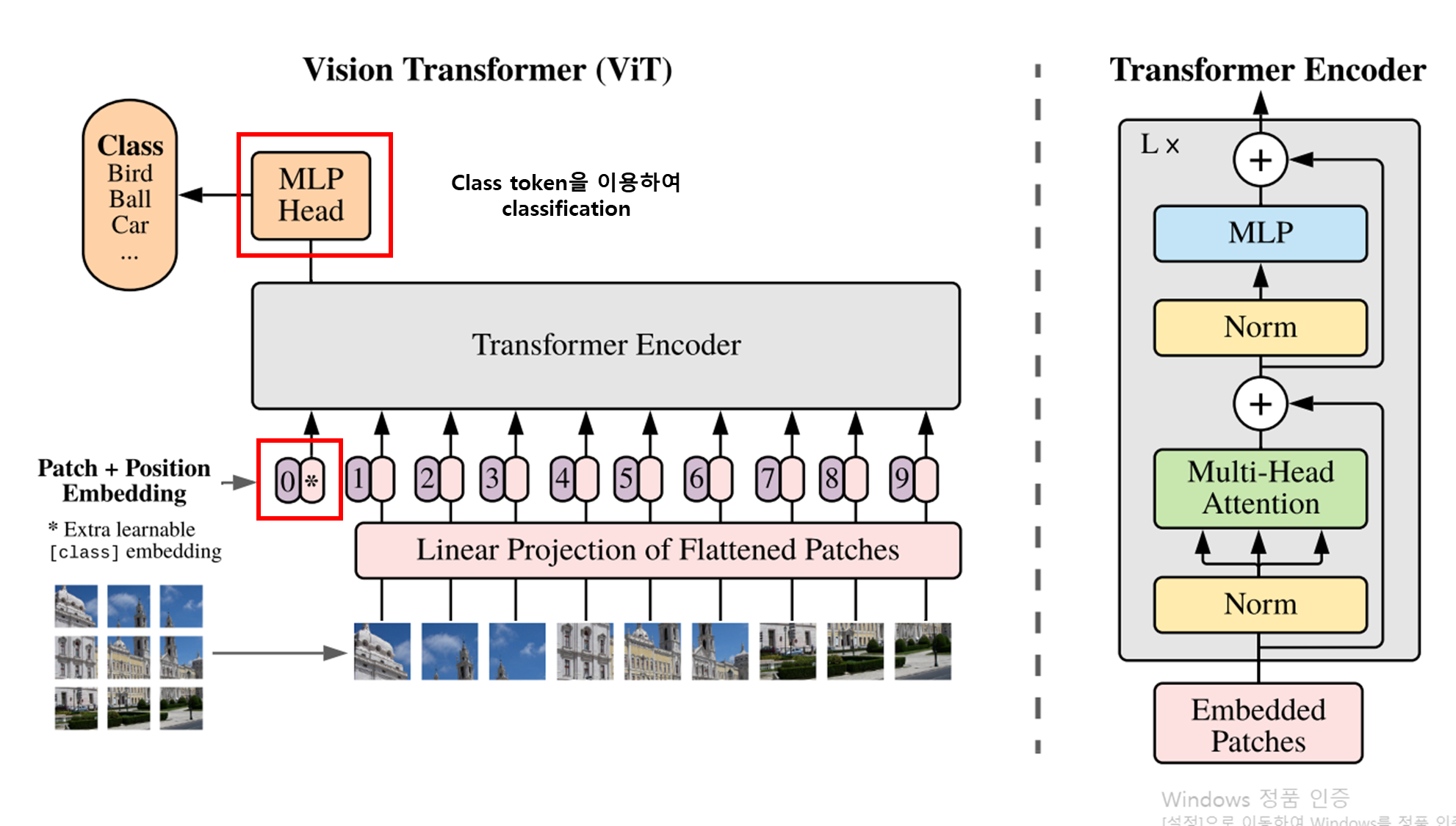
[전체적인 구조]

[Patch]
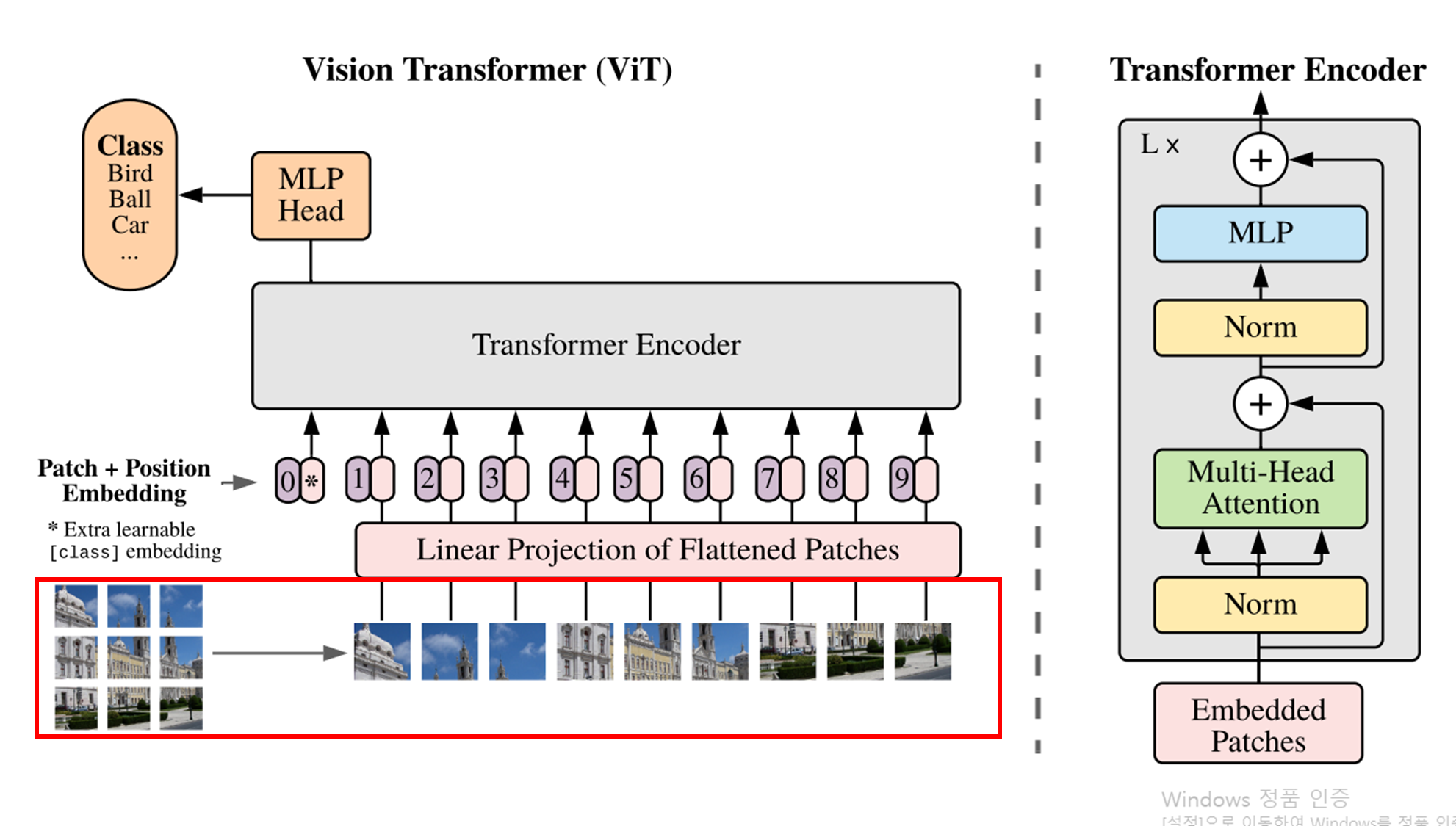
- 위 그림을 보면 patch가 원본 이미지의 왼쪽 위부터 순서대로 들어가는 걸 확인해볼 수 있음
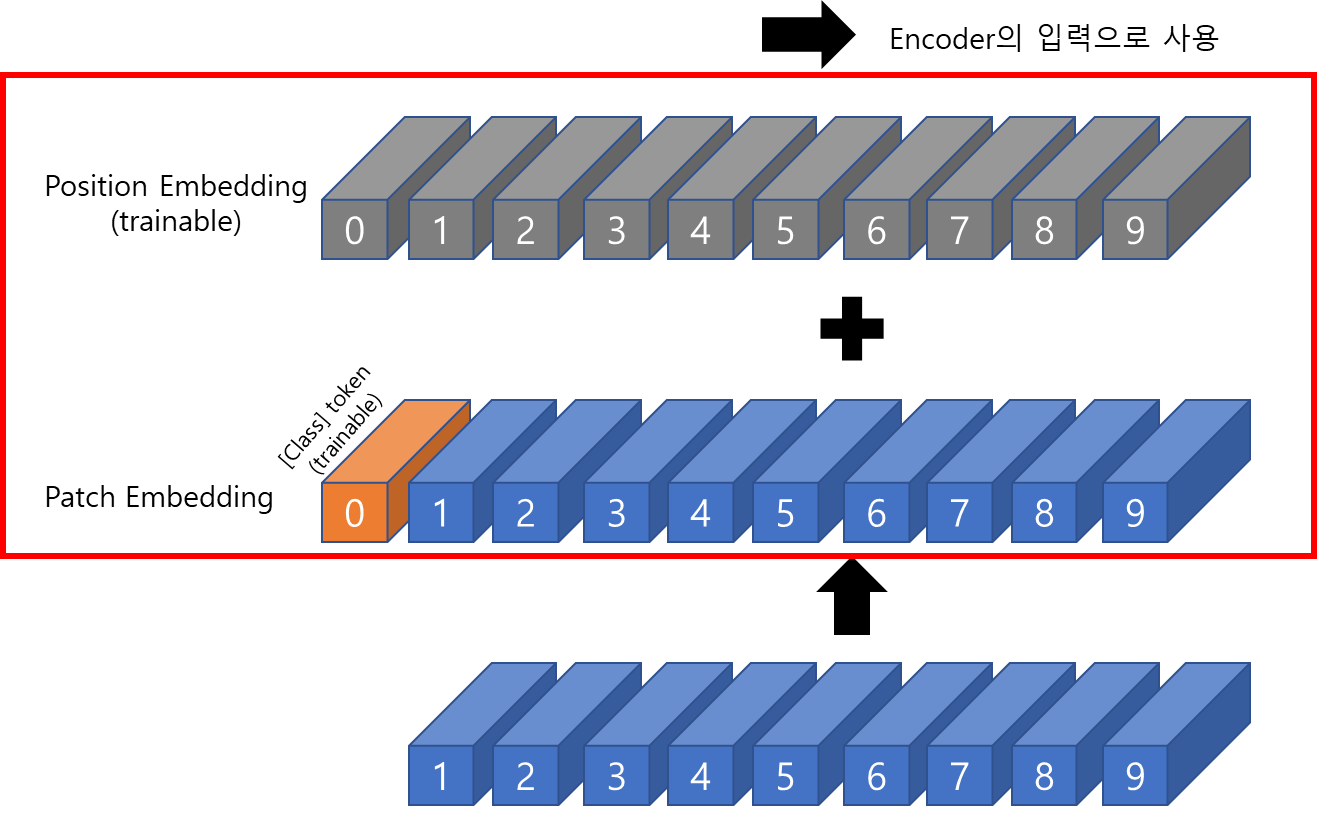
[Patch + Position Embedding]

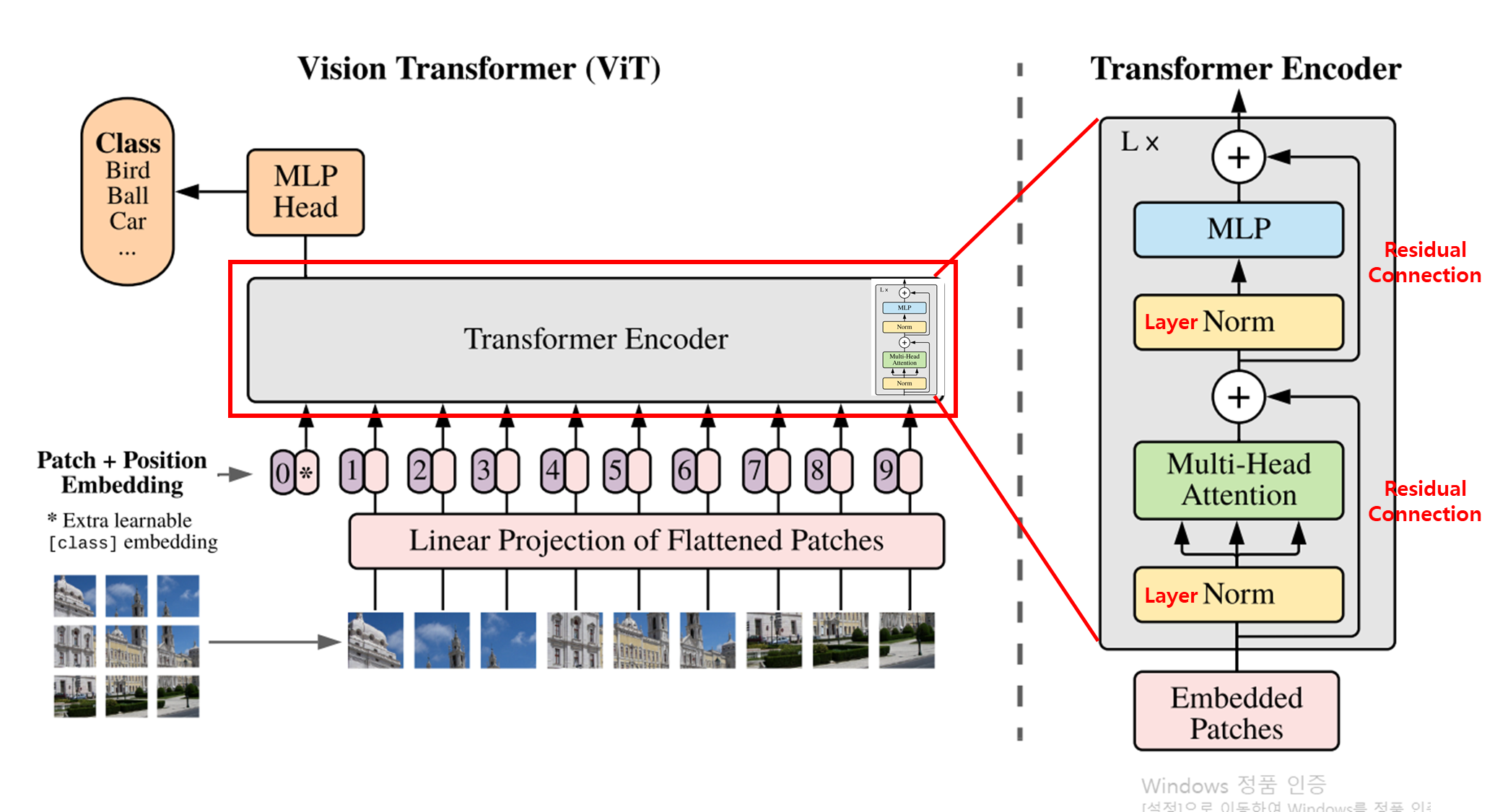
[Encoder]
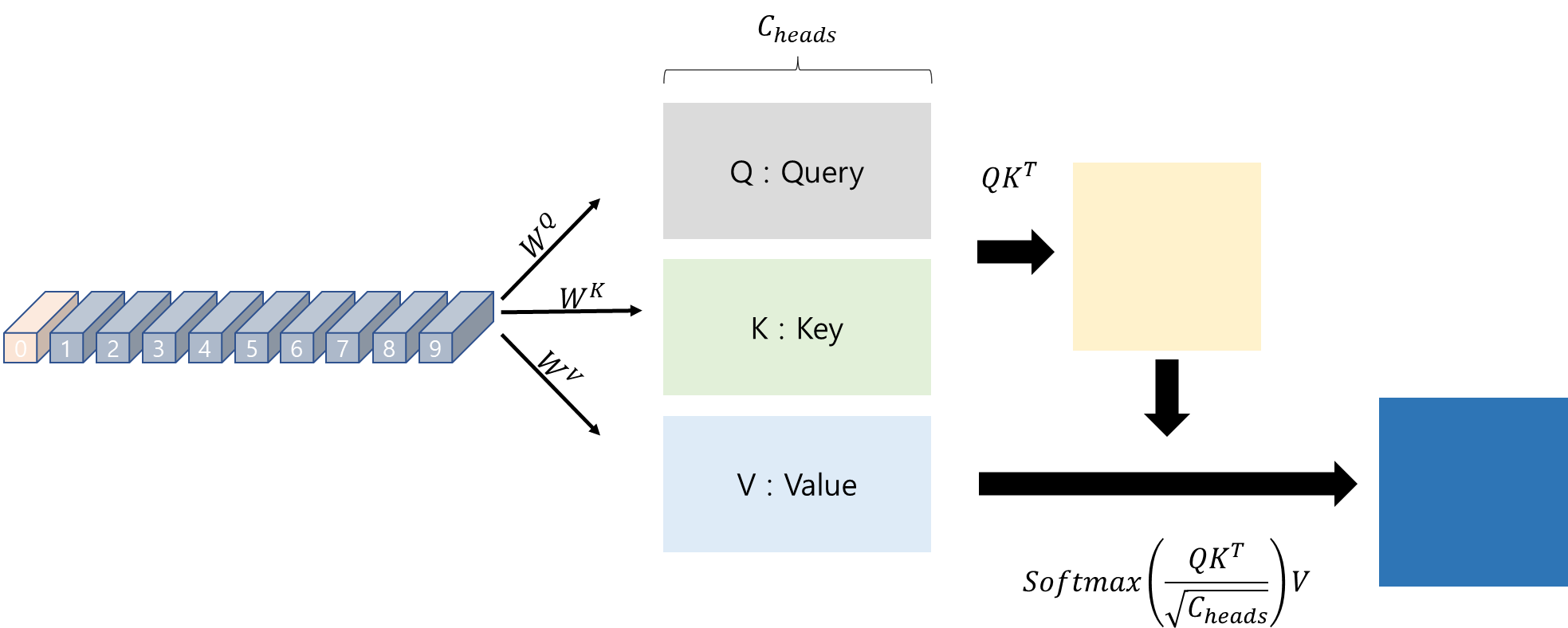
[Multi-Head Attention]

[MLP]

우선 input image를 보자
Input image을 보면 이미지가 각 patch로 나뉘어 모델의 input으로 사용되는 것을 볼 수 있다.
원래의 Transformer는 token embedding의 1D sequence를 input으로 받는다.
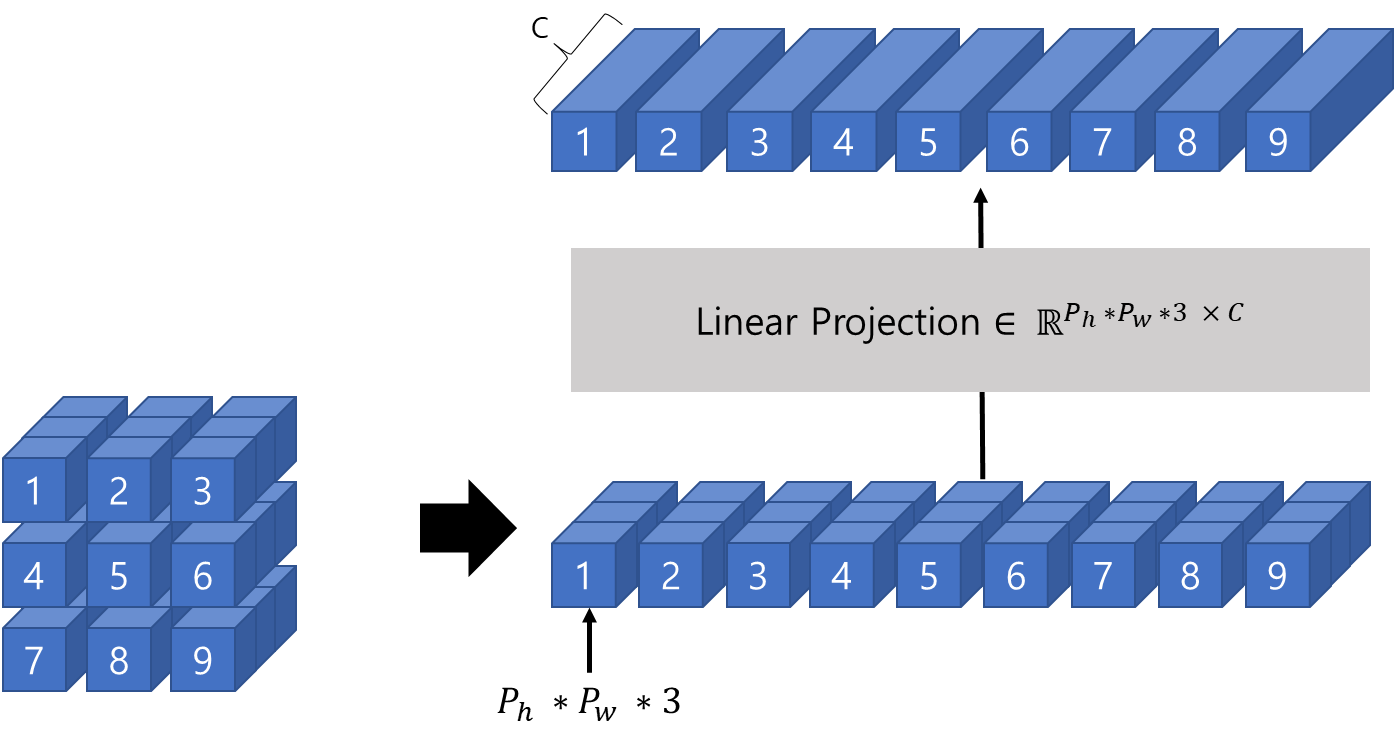
2D image를 transformer로 다루기 위해 원래 이미지를 위 그림과 같이 flatten 2D patch로 reshape 한다.
원래 이미지 사이즈
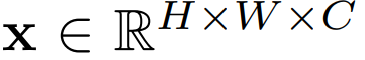
H, W, C = Height, Width, Channel
패치 이미지 사이즈
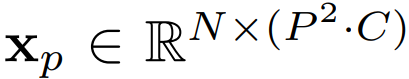
P : Image patch의 사이즈

예시)
Patch size P가 128이고
H, W가 256 이라면
N = 4가 될 것이다.
즉, 128 x 128 x C의 patch가 4개 있는 것과 동일한 것이다.
[Vision transformer 구조]
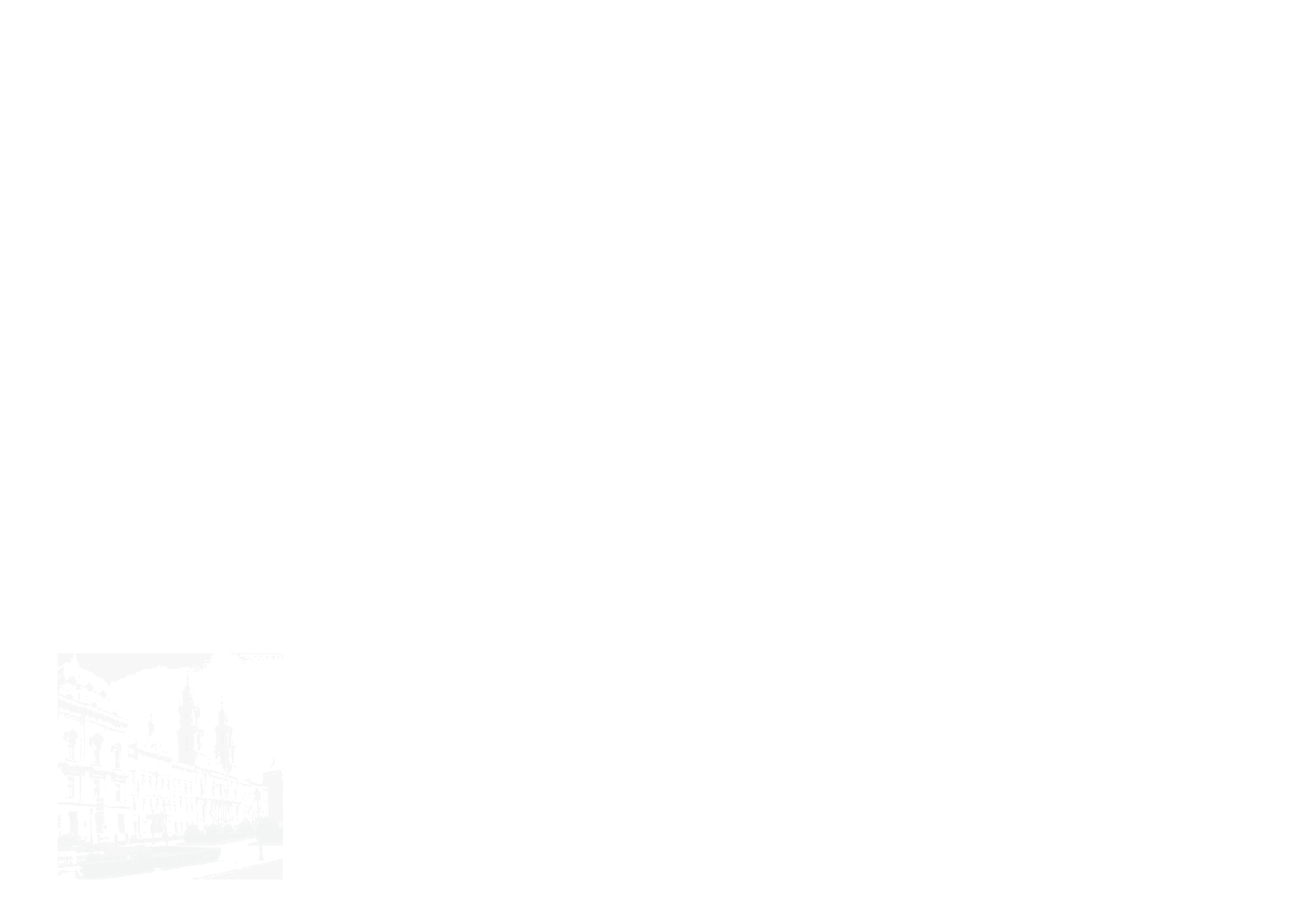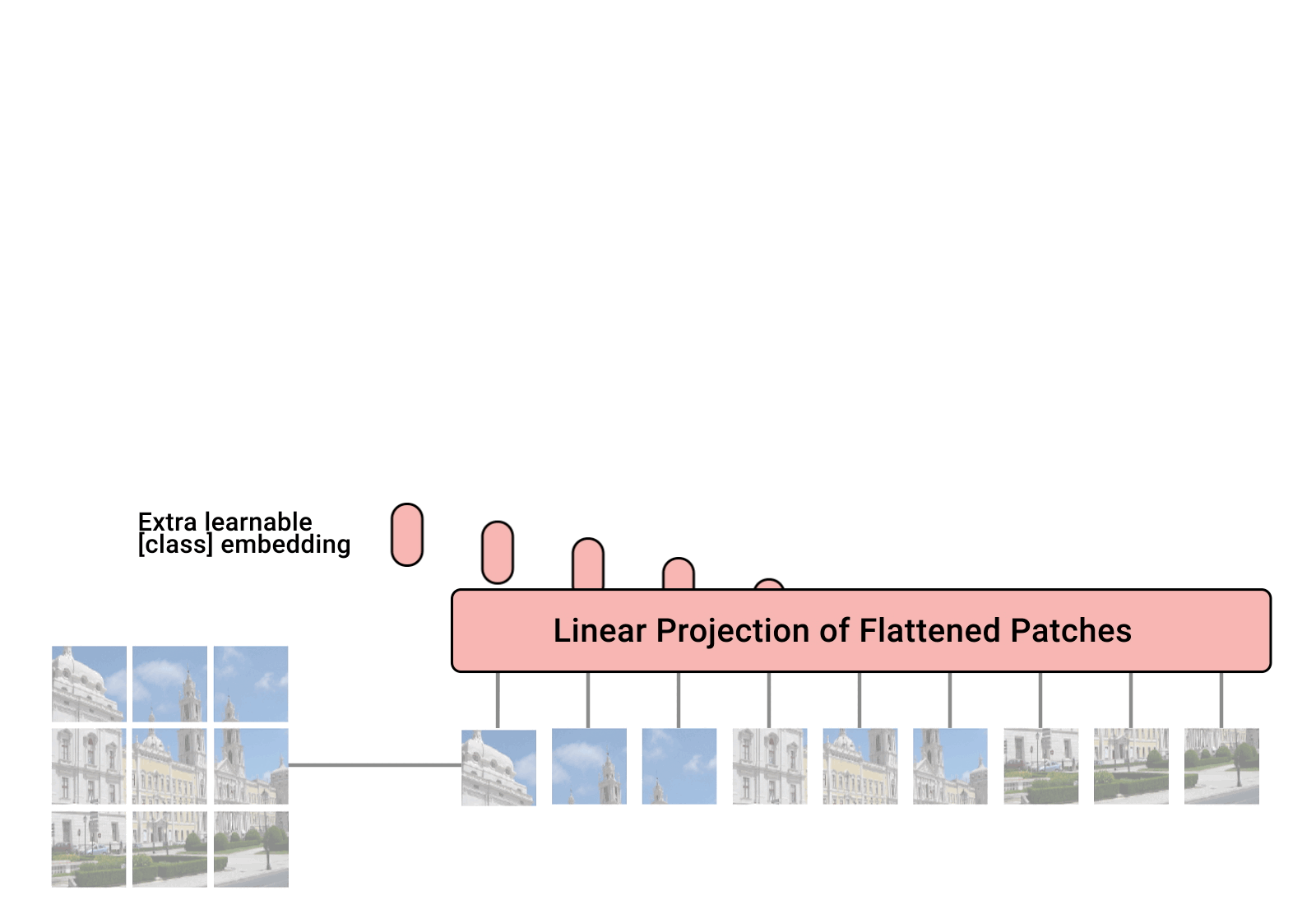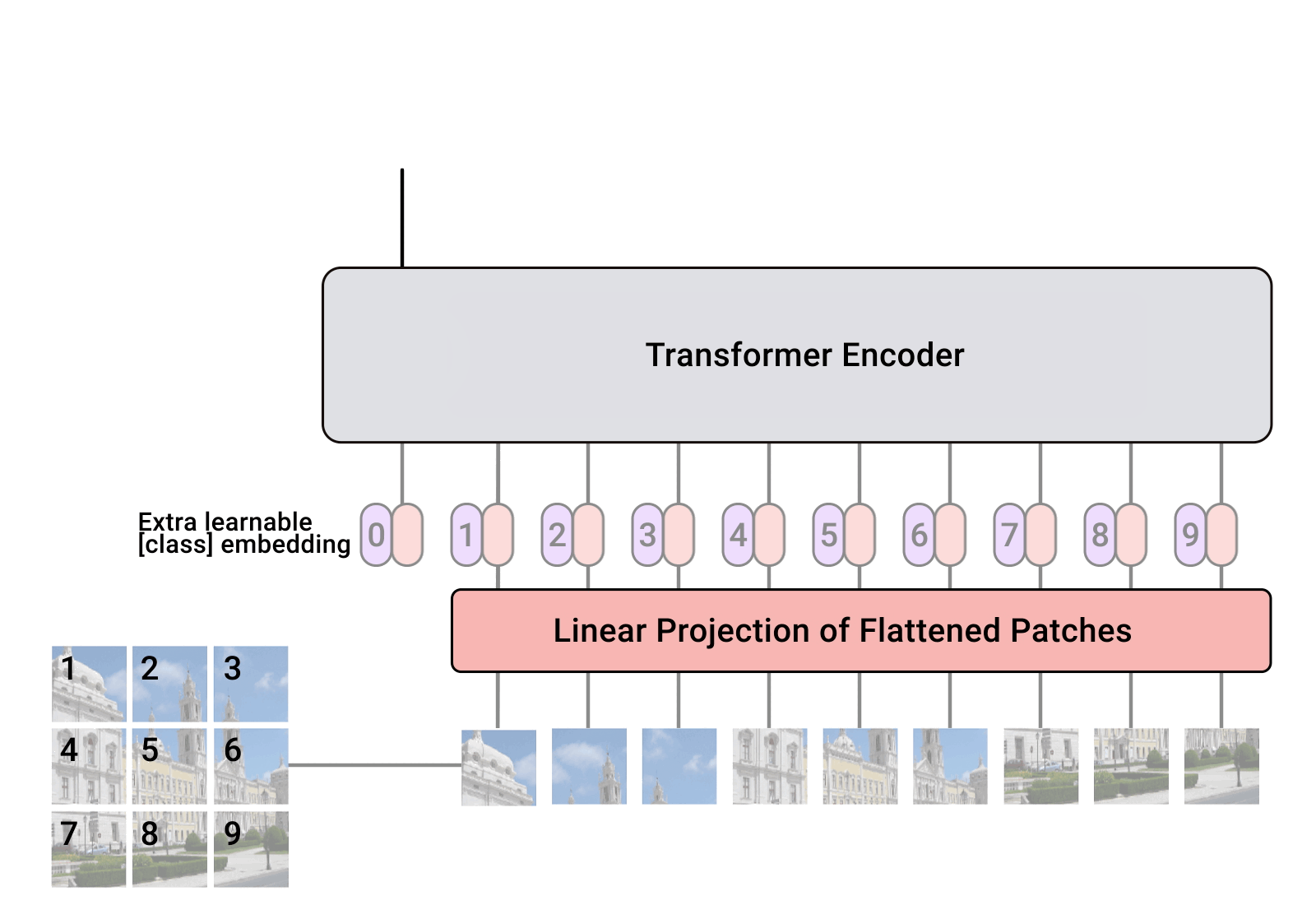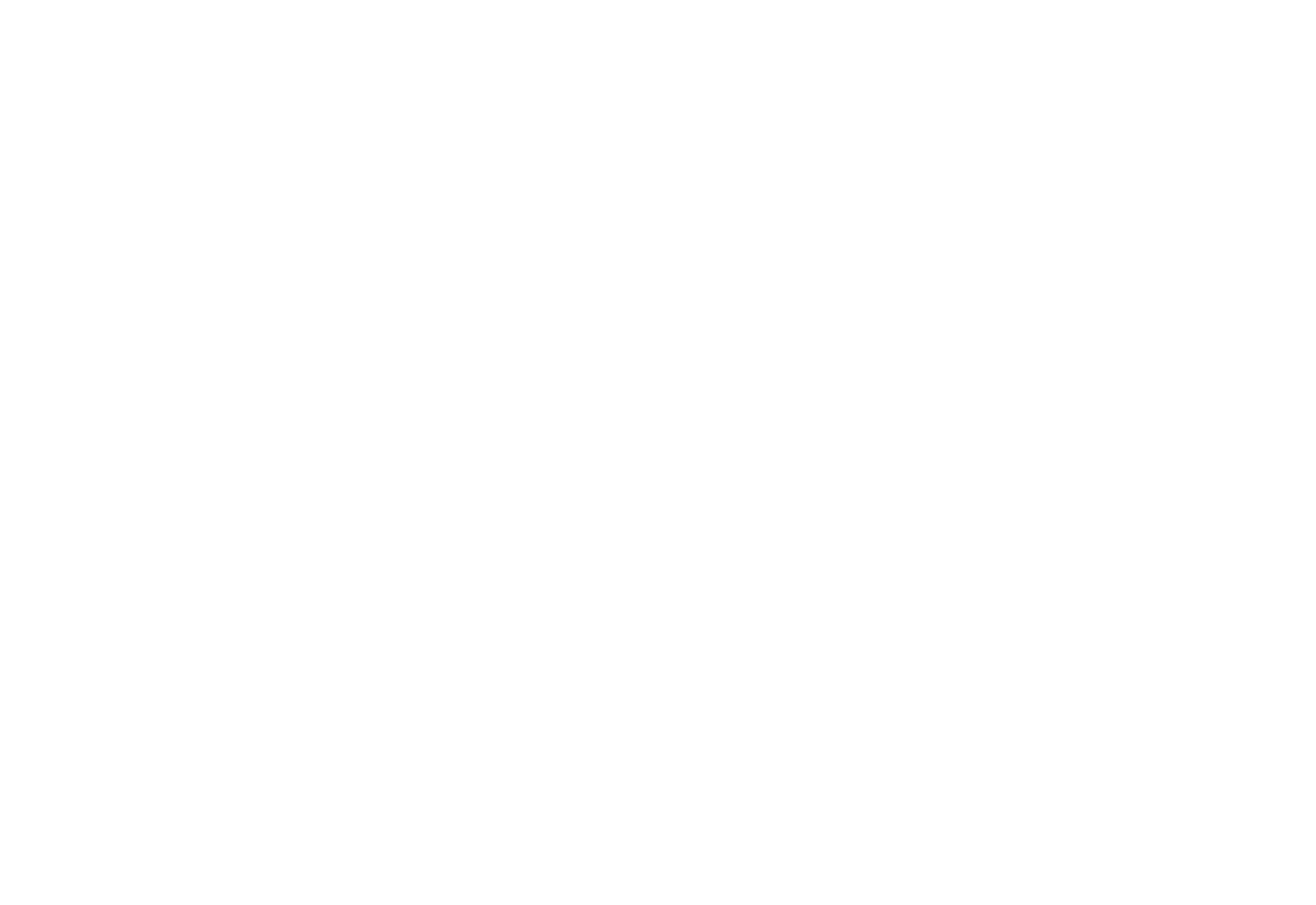
출처 : https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html
CNN는 hand-crafted feature extraction을 피하는 대신
architecture 자체는 이미지용으로 특별히 설계되었으며, computationally demanding할 수 있다.
차세대 scalable vision models을 기대하면서도,
domain-specific한 design이 필요한지,
아니면 더 많은 domain agnostic 하면서 computationally efficient arcitecture를 활용하여 SOTA 결과를 낼지 고민해야 함.
이 방향의 첫 단계로 Vision 기반 transformer model인 ViT(vision transformer)가 제안됨
ViT는 Transformer를 텍스트에 적용할 때 사용되는 word embedding sequence와 유사한,
image patch sequence로 입력 이미지를 나타내고,
이미지에 대한 class label을 예측
ViT는 충분한 데이터에 대해 학습할 때 우수한 성능을 보임
4배 더 적은 computational resource로 SOTA CNN을 능가.
ViT는 CNN에 비해 좋은 결과를 달성하면서도,
pre-training을 위해 더 적은 computational resource를 확보한다.
ViT는 일반적으로 weaker inductive bias를 보여,
더 작은 dataset에서 훈련할 때 model regularization 및 data augmentation에 대한 의존도가 높아짐
inductive bias
학습 모델이 경험하지 않은 주어진 입력의 출력을 예측하는 데 사용하는 가정의 집합
[Vision transformer]
[input image to patch]
ViT는 이미지를 아래와 같이 정사각형 패치 그리드로 나눈다.
CNN은 pixel array를 사용하는 반면,
ViT는 이미지를 visual tokens으로 분할함.

[Linear projection]
각 patch는 patch 안에 있는 모든 pixel들의 channel을 concatenate한 후,
-> desired input dimension에 linearly projecting 한다.
-> 이 결과로 single vector로 flatten된다.
[Position embedding]
transformer는 input element의 구조에 대해 agnostic하기 때문에,
(patch로 나눠 input으로하면 이미지의 위치 정보가 어느 정도 손실됨)
각 patch에 대해 학습가능한 position embeddings를 추가하여
모델이 이미지의 구조를 학습할 수 있도록 함
선험적으로, ViT는 이미지에서 patch의 상대적인 위치 또는 이미지가 2D 구조를 가지고 있다는 사실을 알지 못함.
이에 training data에서 관련 정보를 학습하고 position embeddings에서 structural 정보를 encode 해야 함.
[Encoders]
1. Multi-Head Self Attention Layer (MSP)
- 모든 attention outputs을 올바른 차원에 linearly하게 연결한다.
- 많은 attention heads는 이미지의 local 및 global dependencies를 학습하는데 도움 줌
2. Multi-Layer Perceptrons (MLP) Layer
- Gaussian Error Linear Unit(GELU)가 있는 두 개의 레이어가 포함.
3. Layer Norm (LN)
- Train image간의 새로운 dependencies를 포함하지 않기 때문에 각 block 앞에 추가
- Training time과 overall performance를 향상시키는데 도움.
4. Residual connections
- component가 non-linear activation function을 거치지 않고 네트워크를 통해 직접 흐를 수 있도록 block 뒤에 포함.
[Experiments]
ImageNet data로 학습 후 테스트 했으나 좋은 결과를 기록하지 못함.
-> 이는 ViT가 이미지에 대한 inbuilt knowledge가 부족하여 ImageNet에 over-fit 되었기 때문이라고 함
(즉, 모델이 생각보다 많은 수의 데이터로 학습해야 결과가 잘 나온다는 것을 알 수 있음)
Only ImageNet : ViT < BiT
ImageNet-21k : ViT ≒, BiT
JFT : ViT > BiT
[Visualization]

Left: ViT는 position embedding을 통해 image patch의 grid와 같은 구조를 학습.
Right: ViT의 lower layer에는 global feature과 local feature이 모두 포함되고 higher layer에는 global feature만 포함.
위 이미지는 모델이 학습하는 내용에 대한 직관을 얻기 위해 내부 작동 중 일부를 시각화 한 것.
position embedding을 보고 ViT가 직관적인 이미지 구조를 재현할 수 있음을 알 수 있다.
참조
https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html
Transformers for Image Recognition at Scale
Posted by Neil Houlsby and Dirk Weissenborn, Research Scientists, Google Research While convolutional neural networks (CNNs) have been u...
ai.googleblog.com
https://towardsdatascience.com/are-transformers-better-than-cnns-at-image-recognition-ced60ccc7c8
Are Transformers better than CNN’s at Image Recognition?
Nowadays in Natural Language Processing (NLP) tasks, transformers have become the goto architecture (such as BERT, GPT-3, and so on). On the other hand, the use of transformers in computer vision…
towardsdatascience.com
https://viso.ai/deep-learning/vision-transformer-vit/
Vision Transformers (ViT) in Image Recognition - 2021 Guide - viso.ai
Vision Transformers (ViT) brought recent breakthroughs in Computer Vision achieving state-of-the-art accuracy with better efficiency.
viso.ai
https://www.youtube.com/watch?v=2lZvuU_IIMA
'딥러닝관련 > 기초 이론' 카테고리의 다른 글
| 경사 하강법(Gradient Descent) (0) | 2022.02.20 |
|---|---|
| Swin Transformer (0) | 2021.11.25 |
| Transformer 정리 (0) | 2021.11.09 |
| seq2seq, attention 정리 (0) | 2021.11.08 |
| 선형(linear) vs 비선형(non-linear) (4) | 2021.11.05 |



