이미지 복원 작업은 spatial details 와 high-level contextualized information 사이의 균형이 필요함.
MPRnet은 multi-stage architecture
degraded input에 대한 restoration functions을 점진적으로 학습하여, 전체 restoration process를 보다 관리하기 쉬운 단계로 나눔
특히,
Encoder-Decoder 구조로 -> contextualized feature를 학습
high-resolution branch로 -> local information을 유지
또한, 각 stage에서
local feature를 reweight하기 위해 supervised attention를 활용
(per-pixel adaptive design)
Multi stage에서의 핵심 요소 -> 서로 다른 단계간의 information exchange
MPRnet에서는 earlier stage부터 last stage까지 정보를 교환하는 것 뿐만 아니라
feature processing blocks 간에 lateral connections 진행
(-> 정보 손실을 방지 하기 위해)
이미지 degradation은 원인으로는 noise, blur, rain, haze 등이 있으며, ill-posed problem이다.
(-> 실행 가능한 solution이 매우 많이 존재하기 때문에 ill-posed)
기존의 restoration technique
1. Handcrafted restoration
설계 하기 어려운 작업이며, 일반화하기 어려움
2. Convolutional neural network
위의 handcrafted 문제를 해결하기 위해 나왔으며 대부분 single stage.
Multi-stage network
- Pose estimation, scene parsing, action segmentation 등에서 single stage보다 효과적인 것으로 나타남.
- 그러나 image restoration에서는 multi-stage가 적용이 거의 안됨.
기존의 연구에 근거해봤을 때 multi-stage image restoration은 아래와 같은 architectural bottlenecks가 존재함.
첫 째,
1. Encoder-decoder
-> conextual information을 encoding하는데 효과적임,
그러나 spatial image details는 보존하기 어려움
2. Single-scale pipeline
-> sptial image details는 정확하지만,
semantically 덜 안정적인 output.
-> Image Restoration을 효과적으로 하기 위해서는 multi-stage 구조에서 위 두개를 선택적으로 조합하는 것이 필요
둘 째,
단순히 one stage의 output을 다음 단계로 전달하는 것이 suboptimal result를 낳음.
셋 째,
점진적인 복원을 위해서는, 각 단계에서 supervision 하는 것이 중요함.
마지막,
multi-stage processing 동안, encoder-decoder branch에서 contextualized feature를 보존하기 위해,
intermediate features를 이전 단계에서 이후 단계로 propagate하는 메커니즘이 필요.
위 한계점을 극복하기 위해 MPRnet은 아래와 같은 구조를 사용
1.
Encoder - Decoder, Original Image Resolution
초기 단계 -> encoder-decoder -> multi-scale contextual information 학습
마지막 단계 -> original image resolution -> fine spatial details를 보존
2.
Supervised Attention Module(SAM)
두 stage 사이에 연결ground-truth의 안내에 따라 next stage 로 전달되기 전에, previous stage의 features를 개선하는데 사용되는 attention maps를 계산한다.
3.
CSFF(Cross-Stage Feature fusion)
초기 stage에서 나중 stage로 multi-scale contextualized feature를 전파하는데 도움이 되는 CSFF 추가
단계 간의 정보 흐름을 용이하게 하여 multi-stage network optimization을 안정화하는데 효과적.
MPRnet
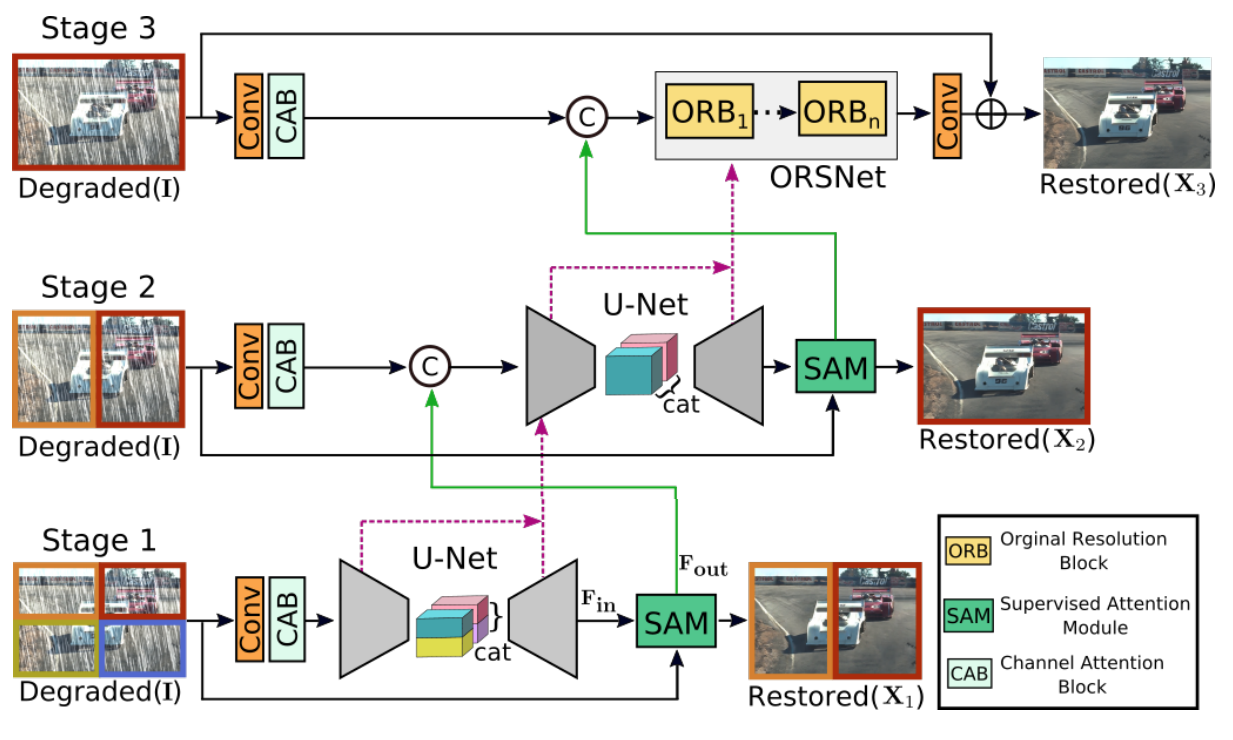
위는 MPRnet의 전체적인 구조

위의 처음 두 단계는 broad contextual information을 학습(encoder-decoder)

이미지 복원은 위치에 민감한 작업
(입력 - 출력 pixel by pixel 대응이 필요함)
-> 따라서 마지막 단계에서 original input image resolution에서 작동하는 sub 네트워크를 사용
(without down-sampling)
단순히 여러 단계를 통합하는 대신,
두 단계 사이에, supervised attention module을 통합.
Cross-stage feature fusion mechanism 도입
(초기의 중간 multi-scale contextualized feature -> 후자에 중간 feature를 통합)
각 단계가 모두 입력 이미지에 액세스 가능
입력 이미지에 다중 패치를 적용하고 겹치지 않게 분할.
Loss function
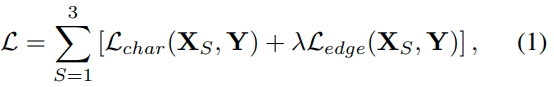

L_char : Charbonnier loss
L_edge : edge Loss
λ : 0.05
Charbonnier Loss

L2 Loss 에 epsilon(1e-3)을 추가
-> small error 에 더 robust하고 training 중에 더 나은 convergence를 유지하기 위해.

Edge Loss
Charbonnier Loss

∆ : Laplacian operator
high frequency의 details의 신뢰성을 향상 시키기 위해

[Complementary Feature Processing]
Encoder-Decoder
-> 입력 : 저해상도
-> 출력 : 고해상도
multi scale information를 효과적으로 encoding 하지만,
down-sampling 작업의 반복으로 인해 spatial details가 희생
Single stage feature pipeline
fine spatial details가 있는 이미지를 생성하는데 신뢰할 수 있음.
그러나 limited receptive field로 인해 semantically less robust 하다.
(즉 Encoder-decoder - single stage feature pipeline은 상호 보완적으로 볼 수 있음)
때문에 MPRnet은 위 두 개를 같이 사용함.
- Encoder-Decoder Subnetwork -

구조는 standard U-Net
그 안에 Channel Attention Blocks(CABs)를 넣음.
(Downsampling, upsampling 하는 과정에)
-> 각 scale에서 feature를 extract 하기 위해

CAB의 구조는 위와 같음(위의 dotted box)

U-Net의 skip connection feature map도 CAB로 처리됨
Bilinear interpolation O
Transposed Convolution X
(Transposed Convolution 사용시 checkerboard artifacts 비슷하게 생겨남)
- Original Resolution Subnetwork -
Input Image에서 output 이미지까지의 details를 유지하기 위해 마지막 단계에서
original resolution subnetwork (ORSNet)을 도입.
ORSNet은 downsampling operation이 없으며 spatially-enriched high-resolution features를 생성.
여러 Original Resolution Block으로 구성되며 ORB에는 CAB가 추가로 포함됨.
- Cross-stage Feature Fusion -

Encoder-Decoder - Encoder
및
Encdoer-Decoder - ORSnet
사이에 Cross-stage Feature Fusion (CSFF) 을 도입
* Stage one에서는 다음 stage로 propagate 되기 전에 1 x 1 convolution으로 refined.
CSFF의 장점
1. Encoder-decoder에서 반복적인 up-sampling 및 down-sampling 동작으로 인한
information loss에 따른 network의 취약성을 감소
(이전 stage의 feature도 계속 가져가고 있기 때문)
2. 한 단계의 multi-scale feature는 다음 stage의 features를 풍부하게 하는 데 도움이 됨
3. 정보의 흐름을 용이하게 하여 보다 안정적이되어 전체 구조에 여러 단계를 추가할 수 있음
- Supervised Attention Module -
각 단계 사이에 supervised attention module을 추가함으로써 성능 향상을 할 수 있음.

크게 두 가지 장점이 있다.
1. 각 단계에서 progressive image restoration에 유용한 ground-truth 감시 신호 제공
(위 부분에서 각 stage에서 loss가 restored와 target 사이에서 계산되니 언급한듯 하다)
2. Local supervised predictions의 도움으로,
현재 단계에서 less informative features를 억제하고
useful features만 propagate되도록 attention map을 생성.
SAM 초기 input F_in은
H x W x C를 취하고
아래와 같이 1x1 convolution을 이용하여
residual image(R_s) H x W x 3을 생성한다.

Degraded Image + R_s(residual image)와 결합하여 restored image를 얻는다.
이 restored image(X_s)에 대해 ground-truth image로 explicit supervision을 제공
다음,
1 x 1 convolution -> sigmoid activation을 사용하여
per-pixel attention mask를 얻는다.
이 attention mask를 사용하여 local feature F_in을 다시 보정(1x1 conv)하여
identity mapping path에 추가되는 attention guided features를 생성.
마지막으로 SAM에 의해 생성된 attention augmented feature representation(F_out)은
추가 처리를 위해 다음 단계로 전달.
'Computer-vision' 카테고리의 다른 글
| Optical blur(spatial response) estimation (0) | 2020.12.31 |
|---|---|
| Super-resolution 과 blur removal (0) | 2020.12.31 |
