IoU (Intersection over Union)
- Object에 대한 prediction이 정확한지 여부를 결정하기 위해 IoU 또는 Jaccard Index가 사용됨.
- Prediction bbox와 실제 bbox의 교집합(intersection)을 합집합(union)으로 나눈 교차 값으로 정의.
- Prediction이 "IoU > threshold"면 True Positive / "IoU < threshold"이면 False Positive로 간주.

한마디로, predicted box와 ground truth box의 겹친(overlapping) 영역으로 보면 된다.
일반적으로, IoU가 일부 threshold 값보다 큰 모든 bounding box candidates를 유지한다
Detection 성능을 보다보면 mAP@0.5 = 46.5 이런식으로 수치가 나온다.
이 때 @0.5는 prediction box와 ground truth box가 50% 이상 overlap되면 positive box로 여긴다는 의미이다.
(threshold → 0.5)
이 0.5 IoU threshold 수치가 높아질수록 더 정확하고 확실한 box에 대해서만 평가하기 때문에 최종 성능이 감소할 수 있다.
Precision and Recall
· Recall True Positive Rate, 모든 actual positives에서 true positive predictions가 몇개인지
· 실제 object에 대해서 predict box가 탐지했는지에 대한 여부 (이미지 내의 object들에 대해 초점)
· "Object 빠트리지 않고 모두 찾았어?"
· Precision: Positive prediction value, 모든 positive predictions에서 true positive predictions가 몇개인지
· Predict box가 제대로 탐지했는지에 대한 여부 (결과 box에 대해서 초점)
· "너가 찾은 box들이 정말 정확한 거 맞아?"
위 Precision과 Recall에 대한 예시를 들어보자
ex)
이미지 내에 새가 5마리 존재(GT)한다고 해보자. 이때 우리의 모델이 2개의 물체 검출(prediction)하고, 1마리는 새로 정확히 맞추었다고 해보자.
그러면
Precision = 1 / 2 = 50%,
Recall = 1 / 5 = 20%.
이번엔 이미지 내에 새가 3마리 존재(GT)한다고 해보자. 이때 우리의 모델 4개의 물체를 검출(prediction)하고, 1마리는 정확히 맞추었다고 해보자.
그러면
Precision = 1 / 4 = 25%
Recall = 1 / 3 = 33.33%
mAP (mean Average Precision)
mAP는 Pascal VOC 데이터일 때와 COCO 데이터셋일 때 구하는 방법에 대해서 조금 차이가 있다고 한다.
Pascal VOC
- mAP를 계산하기 위해서는 먼저 클래스별 AP를 계산.
- 특정 클래스에 대한 ground truth(녹색) 및 bbox 예측(빨간색)을 포함하는 아래 이미지를 봐보자
- BBox의 세부 정보는 아래와 같다.
- 위 그림을 보면 IoU가 threshold 0.5 기준으로 미만이면 False Positive, 이상이면 True Positive로 여긴다.
- 이제 confidence score 기준으로 이미지를 정렬한다.
- (*여기서 confidence score은 그 box에서 class가 특정 object class일 확률이라고 생각하면 된다. ex, 개에 대한 box를 prediction을 했는데 개일 확률이 78%)
- Image2와 같이 단일 object(GB)에 대해 2개 이상의 detection가 있는 경우 IoU가 가장 높은 detection는 TP로 나머지는 FP로

VOC metric에서
- Recall : given rank이상으로 순위가 매겨진 모든 positive examples의 비율
- Precision: positive classes에서 해당 순위 이상의 모든 examples 비율
위 그림을 잘 해석해보자
Acc TP, Acc FP는 위에서부터 내려오면서 누적으로 보면 된다.
- P4: predict 1 / ground truth 3 - positive 1 / negative 0 → (recall : 1/3. precision : 1/1)
- P3: predict 2 / ground truth 3 - positive 1 / negative 1 → (recall : 1/3. precision : 1/2)
- P1: predict 3 / ground truth 3 - positive 2 / negative 1 → (recall : 2/3. precision : 2/3)
- P2: predict 4 / ground truth 3 - positive 2 / negative 2 → (recall : 2/3. precision : 2/4)
위 수치를 보고 알아야할 것은 ground truth box보다 많은 수치의 box가 prediction 되면,
recall의 값은 높아질 수는 있겠지만
precision의 값은 낮아질 수도 있다는 점이다.
어느 정도 recall과 precision이 반비례의 관계를 가지고 있다고 볼 수 있다.
마치 전쟁 중 총(box)을 난사 했을 때, 많은 사람이 맞지만(recall↑), 아군도 맞을 수 있지만(precision↓)
총(box)을 조준해서 발사했을 때, 많은 사람이 맞지는 않지만(recall↓), 적이 맞을 확률이 높다(precision↑)
고 생각하면 되지 않을까 싶다.
- 위 precision 및 recall values를 plotted하여 PR(precision-recall) curve를 얻을 수 있다.
- 이 curve 아래의 영역을 Average Precision이라고 한다.
- (ROC curve의 AUC 영역처럼 average precision도 그래프 아래 영역을 수치로 계산하는듯하다.)
- PR curve는 recall이 절대적으로 증가함에 따라 일종의 zig-zag 패턴을 따르지만, 산발적(sporadic)으로 증가하면 precision이 전반적으로 감소한다.
[VOC 2007]
AP는 precision-recall curve의 모양을 summarize하고, VOC 2007에서, 11개의 동일한 간격[0. 0.1, ...,1] (0 to 1 at step size of 0.1)의 recall level에서 precision value의 average으로 정의.
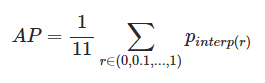
예시 케이스에 대해서는 AP를 위와 같이 정의할 수 있다.
r : recall
p : precision
각 recall level r의 precision은 해당 recall이 r을 초과하는 방법에 대해 측정된 maximum precision을 취하여 interpolate됨

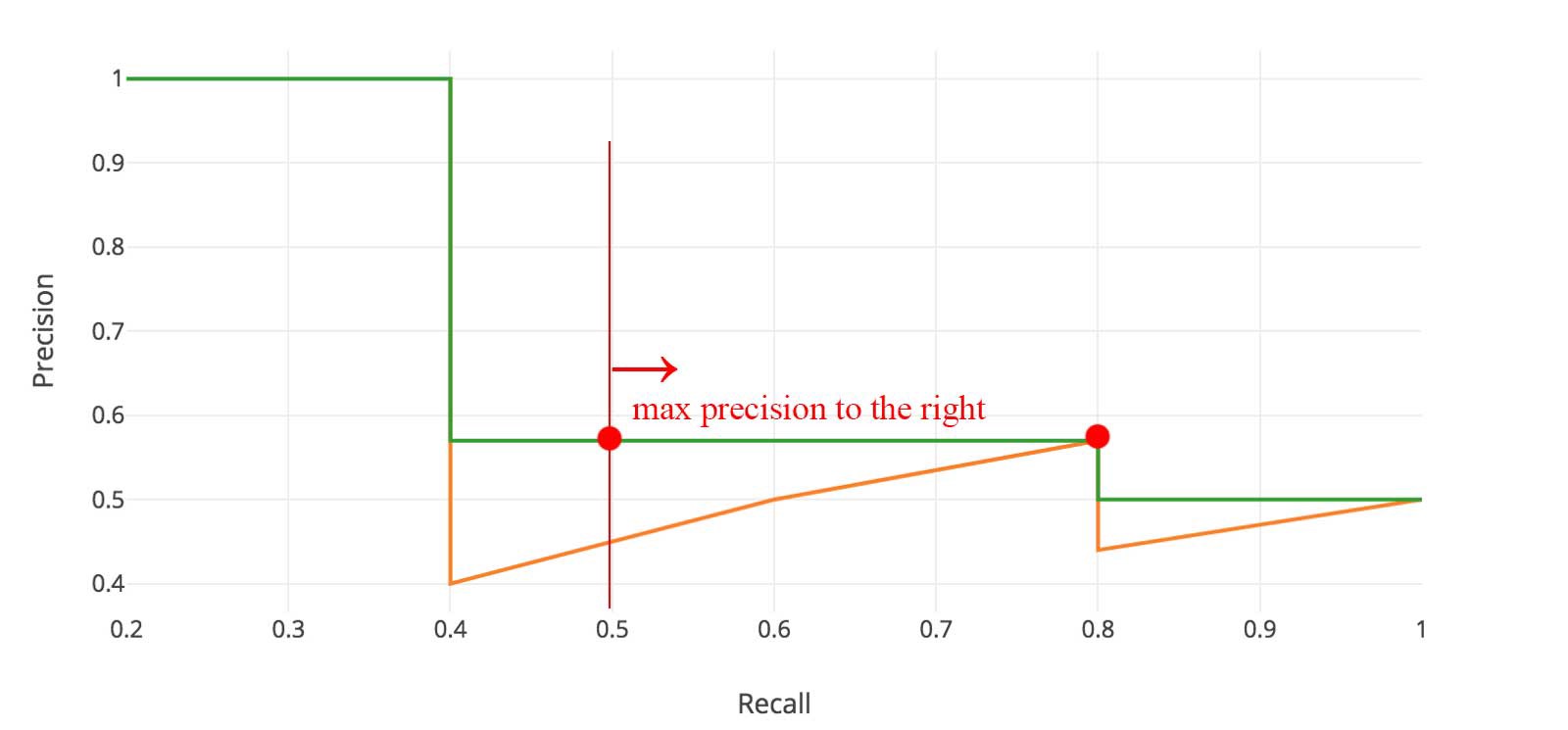
즉, 동일한 간격의 11개 recall point[0: 0.1: 1]에서 오른쪽의 최대 정밀도 값을 취하고 AP를 얻기 위해 평균을 한다.
[VOC 2010]
하지만 VOC 202부터는 AP의 계산 방법이 바뀌었다.
Recall r에 대한 precision을 any recall r에 대해 얻은 maximum precision로 설정하여 precision이 단조록세 감소하는 recall-precision curve에 대해서 계산. 그런 다음 numerical integration에 의해 이 curve 아래의 area로 AP를 계산
즉, 주황색의 PR 곡선이 주어지면 모든 지점에 대해 오른쪽의 maximum precision를 계산하여 green으로 새 curve을 얻음. 이제 green curve 아래 integration을 사용하여 AUC를 가져온다.(=AP).
여기서 VOC 2007과의 차이점은 11가지뿐만 아니라 모든 사항을 고려한다는 것.
위에 근거하여 이제 class(object category)당 AP가 존재하며, 평균 정밀도(mAP)는 모든 object category에 대한 평균 AP입니다.

VOC의 segmentation challenge의 경우 segmentation accuracy(IoU를 사용하여 계산된 per-pixel accuracy)가 평가 기준으로 사용되며 다음과 같이 정의됨

MS COCO
- 일반적으로 VOC에서와 같이 IoU > 0.5인 예측은 True Positive 예측으로 간주
- IoU 0.6과 0.9의 두 예측이 동일한 weightage를 갖는다는 것을 의미.
- 따라서 certain threshold는 evaluation metric에 bias가 발생.
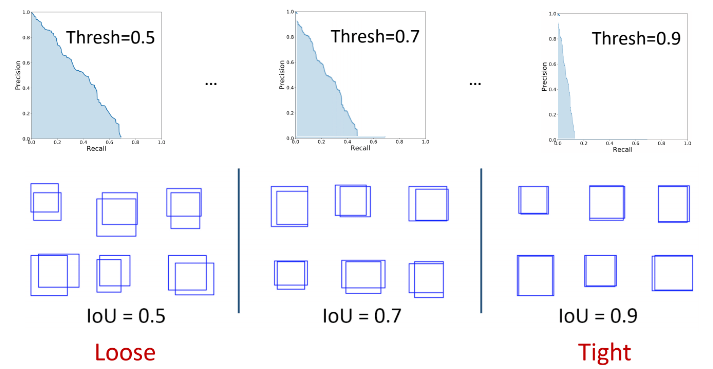
- 이 해결하기 위해 IoU threshold 범위를 사용하고 각 IoU에 대한 mAP를 후 평균을 취하여 최종 mAP를 얻는 것.
COCO evaluation을 위해 [0: .01: 1] R=101 recall threshold를 사용.
COCO evaluation에서 IoU threshold range는 AP@[.5:.05:.95]로 표시되는 0.05의 step size와 함께 0.5에서 0.95 사이.
IoU=0.5 및 IoU=0.75와 같은 고정 IoU의 AP는 각각 AP50 및 AP75로 작성.
- 달리 지정되지 않는 한, AP와 AR은 여러 IoU값에 대해 평균을 냄.
- 특히 .50:.05:0.95의 10 IoU threshold를 사용. -> (0.50, 0.55, 0.60 ... 0.95)
- 이는 AP가 .50의 단일 IoU로 계산되는 전통 방법에 대해 벗어난 것.
- IoU에 대한 평균화는 더 나은 localization을 가진 detector가 된다

AP는 모든 categories(classes)에 대한 평균. 전통적으로 이것을 mean Average Precision(mAP)라고 한다.
AP와 mAP에 대해서 구분하지 않으며, 문맥상 명확하다고 가정
보통 평균은 다른 순서로 취해지며 (최종 결과는 동일), COCO에서는 mAP를 AP라고 함.
- Step 1 : 각 클래스에 대해 서로 다른 IoU threshold에서 AP를 계산하고 평균을 취하여 해당 클래스의 AP를 구함

- Step 2 : 다른 클래스에 대한 AP를 평균화하여 최종 AP를 계산
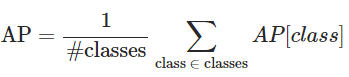
AP는 실제로 average, average, average Precision.
(1. average : recall에 따른 precision 평균
2. average : IoU threshold range에 따른 평균
3. average : 전체 class에 대한 평균)

'딥러닝관련 > Detection' 카테고리의 다른 글
| YOLOv5 PyTorch 돌려보기 (작성 중) (0) | 2023.01.18 |
|---|---|
| SSD(single shot detector)를 활용한 지폐 detection 웹캠 결과 (0) | 2022.07.28 |
| Tutorial to Object Detection (0) | 2022.07.10 |
| Jaccard 계수 (Jaccard coefficient) (0) | 2022.07.06 |
| Single shot detector에서 bounding box 예측(offset 및 SSD output based) (0) | 2022.07.04 |


